時間序列
本用戶指南章節概述串流運算式和數學運算式中提供的一些時間序列功能。
時間序列彙總
timeseries 函數會利用 Solr 的內建分面和日期數學功能,執行快速、分散式時間序列彙總。
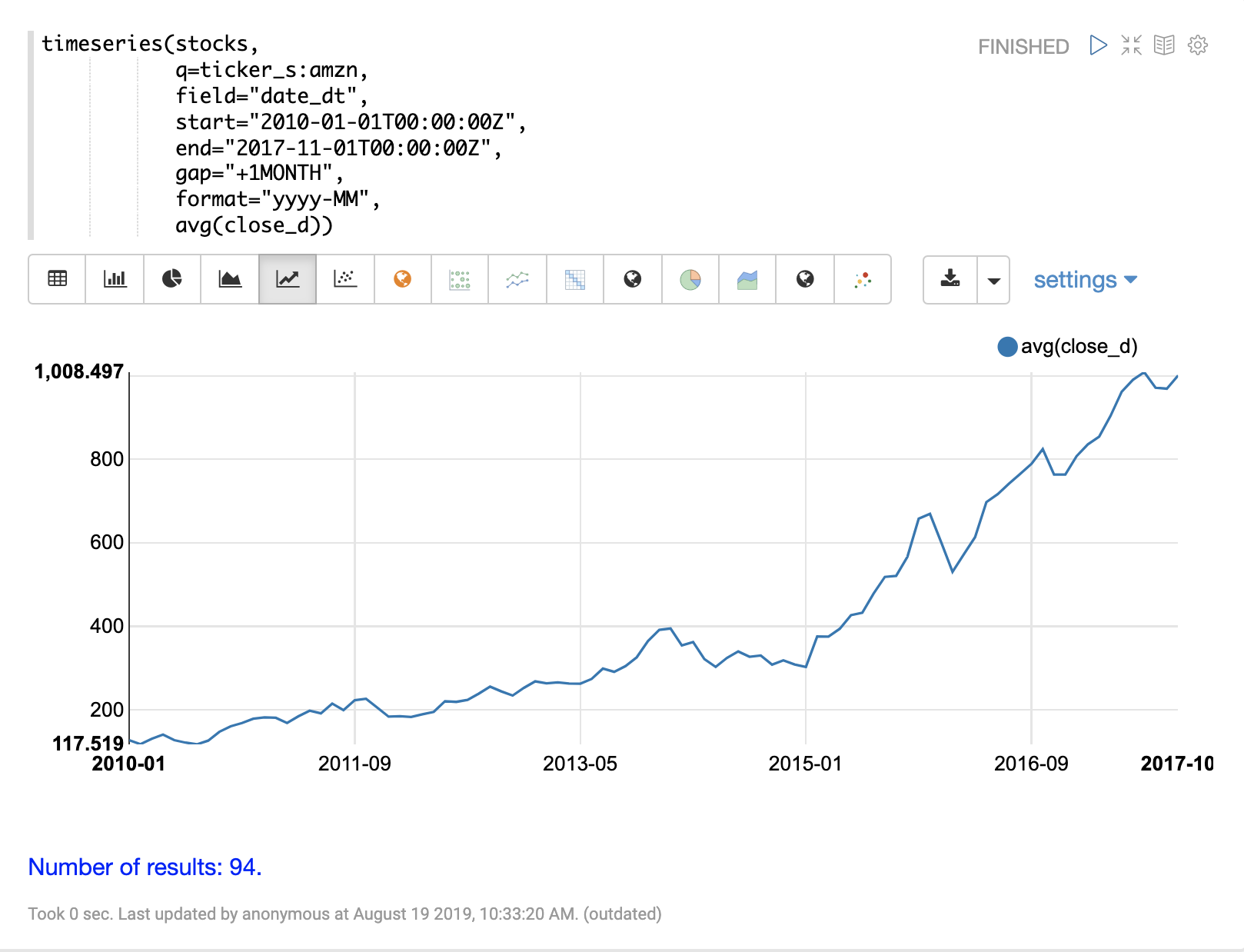
以下範例會對每日股票價格資料的集合執行每月時間序列彙總。在此範例中,會計算特定日期範圍內股票代碼 AMZN 的每月平均收盤價。
timeseries(stocks,
q=ticker_s:amzn,
field="date_dt",
start="2010-01-01T00:00:00Z",
end="2017-11-01T00:00:00Z",
gap="+1MONTH",
format="YYYY-MM",
avg(close_d))當此運算式傳送至 /stream 處理器時,會回應:
{
"result-set": {
"docs": [
{
"date_dt": "2010-01",
"avg(close_d)": 127.42315789473685
},
{
"date_dt": "2010-02",
"avg(close_d)": 118.02105263157895
},
{
"date_dt": "2010-03",
"avg(close_d)": 130.89739130434782
},
{
"date_dt": "2010-04",
"avg(close_d)": 141.07
},
{
"date_dt": "2010-05",
"avg(close_d)": 127.606
},
{
"date_dt": "2010-06",
"avg(close_d)": 121.66681818181816
},
{
"date_dt": "2010-07",
"avg(close_d)": 117.5190476190476
}
]}}使用 Zeppelin-Solr,可以使用折線圖視覺化此時間序列。
向量化時間序列
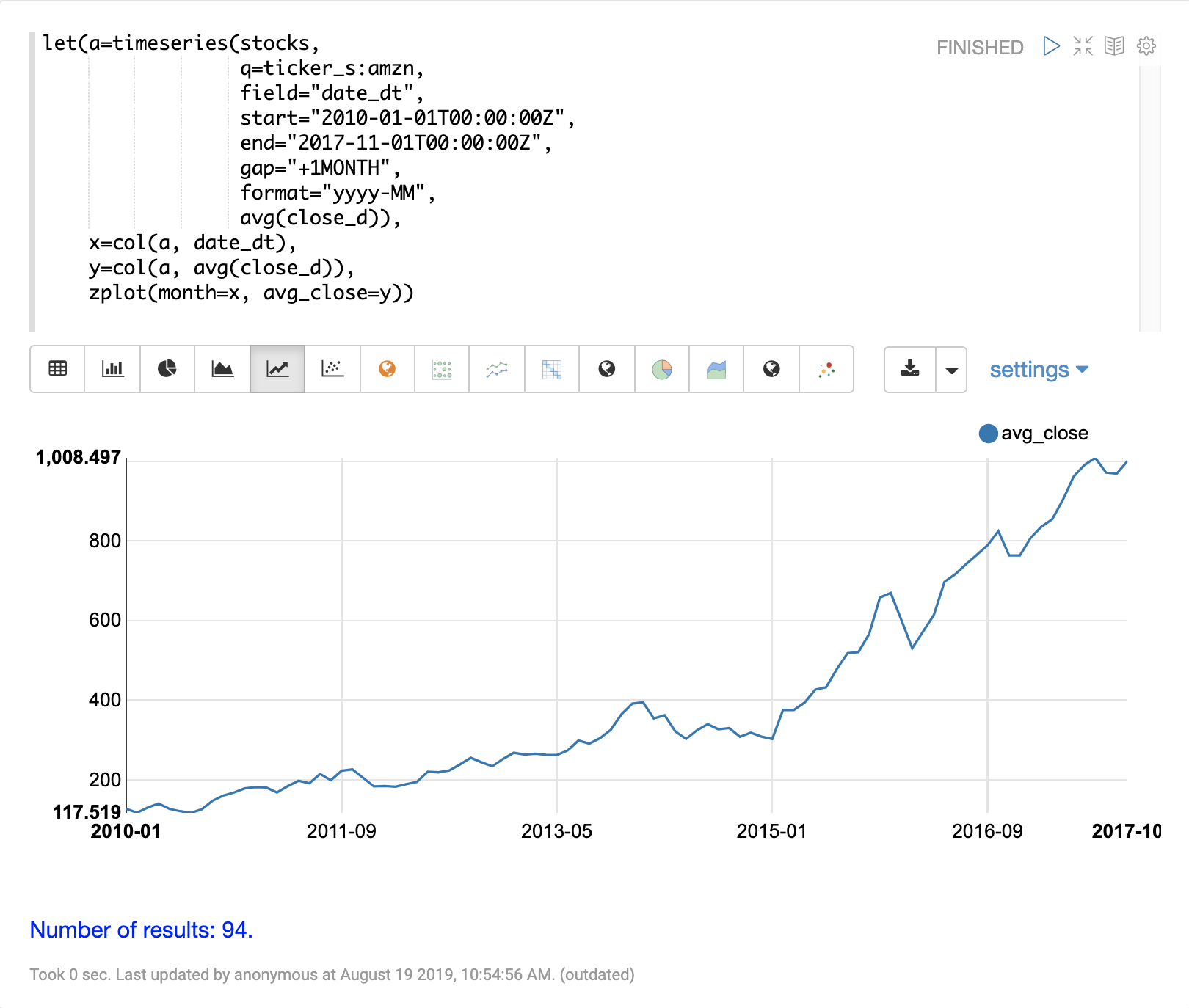
在平滑或建模時間序列之前,需要將資料向量化。col 函數可用於將資料的欄從元組清單複製到陣列中。
以下運算式示範如何將 date_dt 和 avg(close_d) 欄位向量化。然後使用 zplot 函數,在 x 軸上繪製月份,在 y 軸上繪製平均收盤價。
平滑
時間序列平滑通常用於消除時間序列中的雜訊,並協助找出潛在趨勢。數學運算式庫有三種用於時間序列平滑的滑動視窗方法。這些方法使用滑動資料視窗的摘要值來計算一組新的平滑資料點。
這三個滑動視窗函數是延遲指標,這表示它們直到趨勢影響滑動視窗的摘要值時才開始朝趨勢的方向移動。由於這種延遲特性,這些平滑函數通常用於確認趨勢的方向。
移動平均
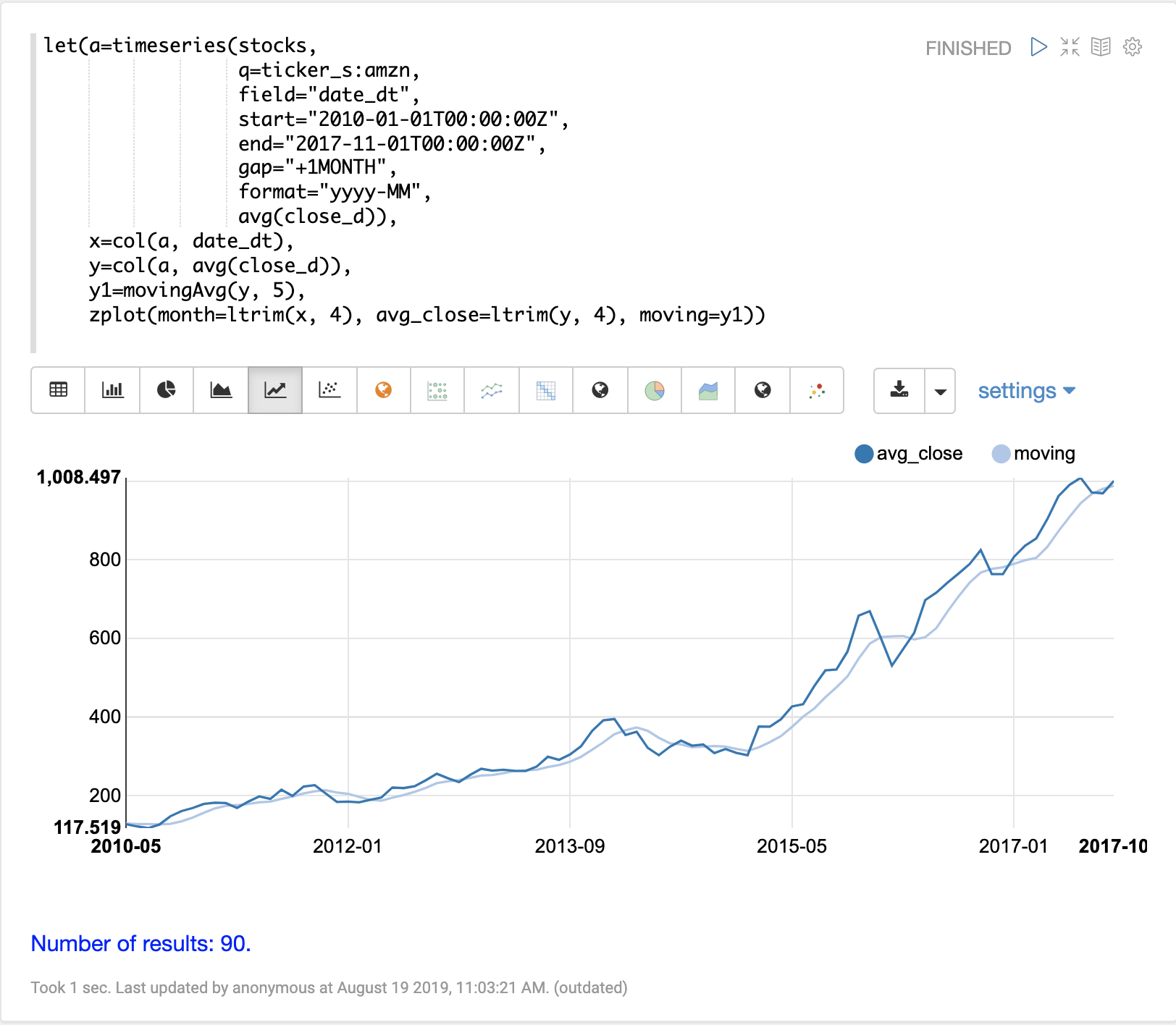
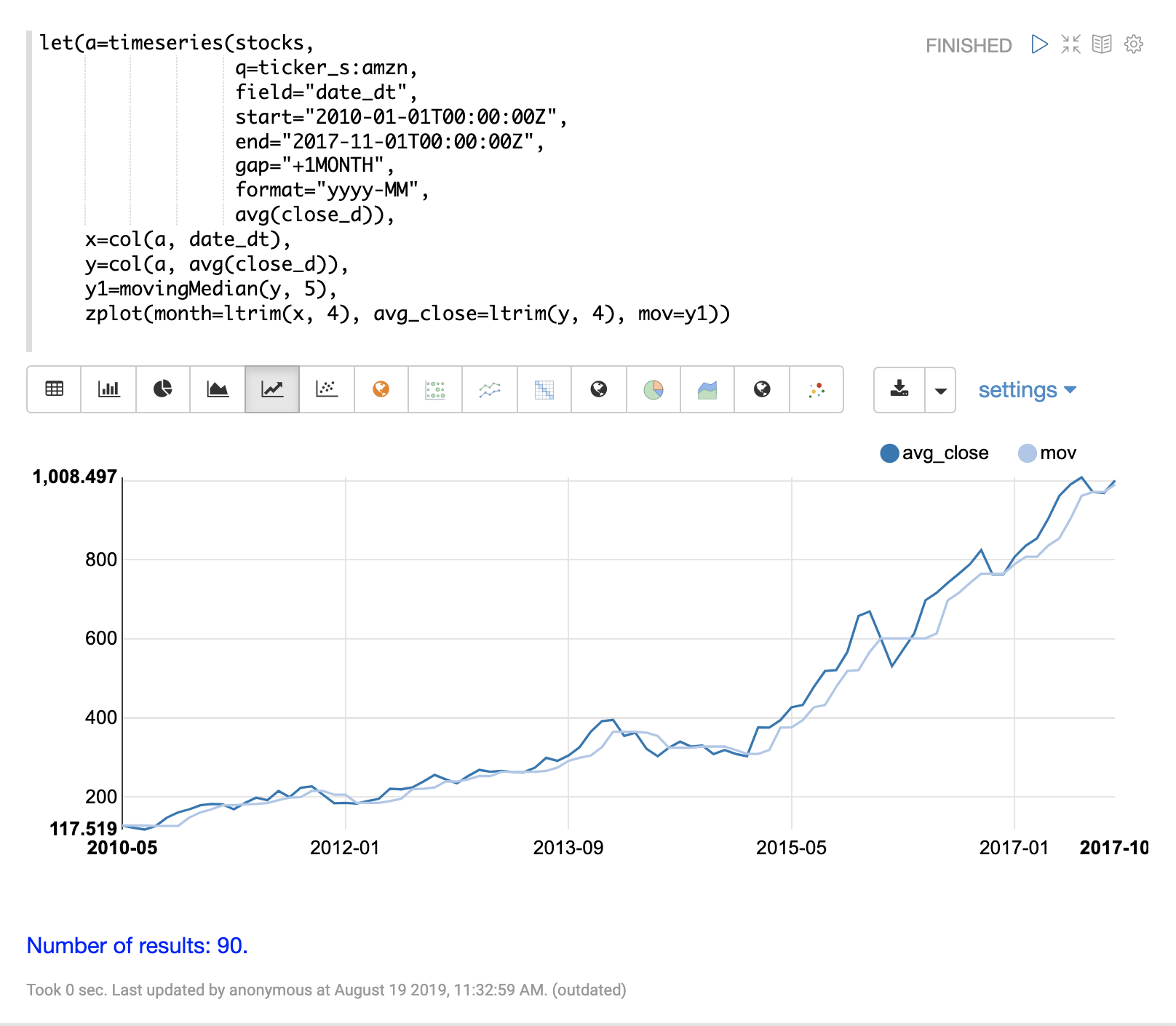
movingAvg 函數會計算資料滑動視窗的簡單移動平均。以下範例會產生時間序列,將 avg(close_d) 欄位向量化,並計算視窗大小為 5 的移動平均。
移動平均函數會傳回一個長度比原始向量短的陣列。這是因為只有在有完整資料視窗可供計算平均值時才會產生結果。如果視窗大小為 5,則移動平均將在第 5 個值開始產生結果。先前的值不會包含在結果中。
然後使用 zplot 函數,在 x 軸上繪製月份,在 y 軸上繪製平均收盤價和移動平均。請注意,ltrim 函數用於從 x 軸和平均收盤價中修剪前 4 個值。這樣做是為了對齊這三個陣列,使它們從第 5 個值開始。

差分
差分可用於透過移除序列中的趨勢或季節性,使時間序列保持平穩。
一階差分
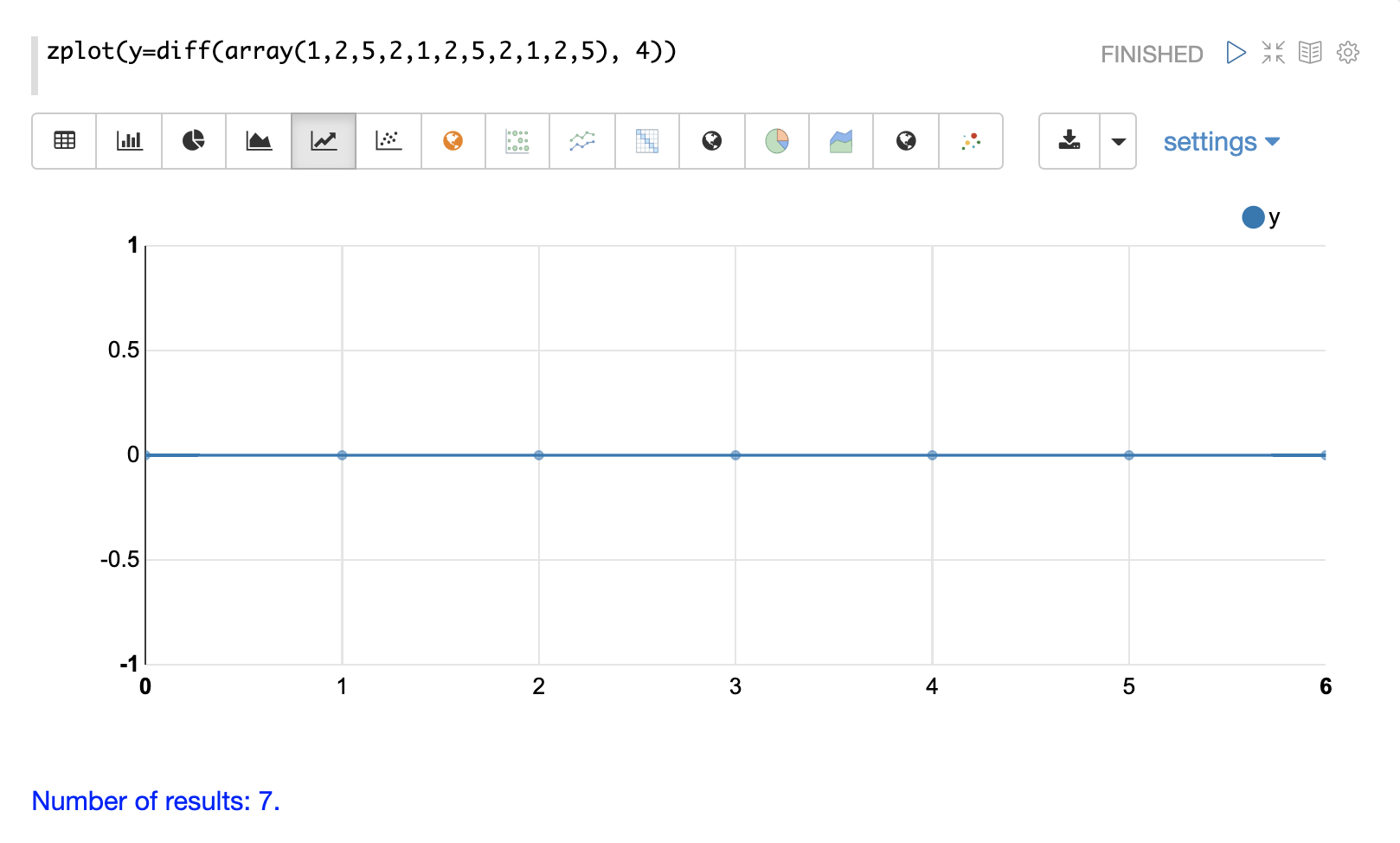
差分技術的核心概念是使用數值之間的差異,而非原始數值。一階差分取的是數值與其前一個數值之間的差。一階差分常被用於去除時間序列中的趨勢。
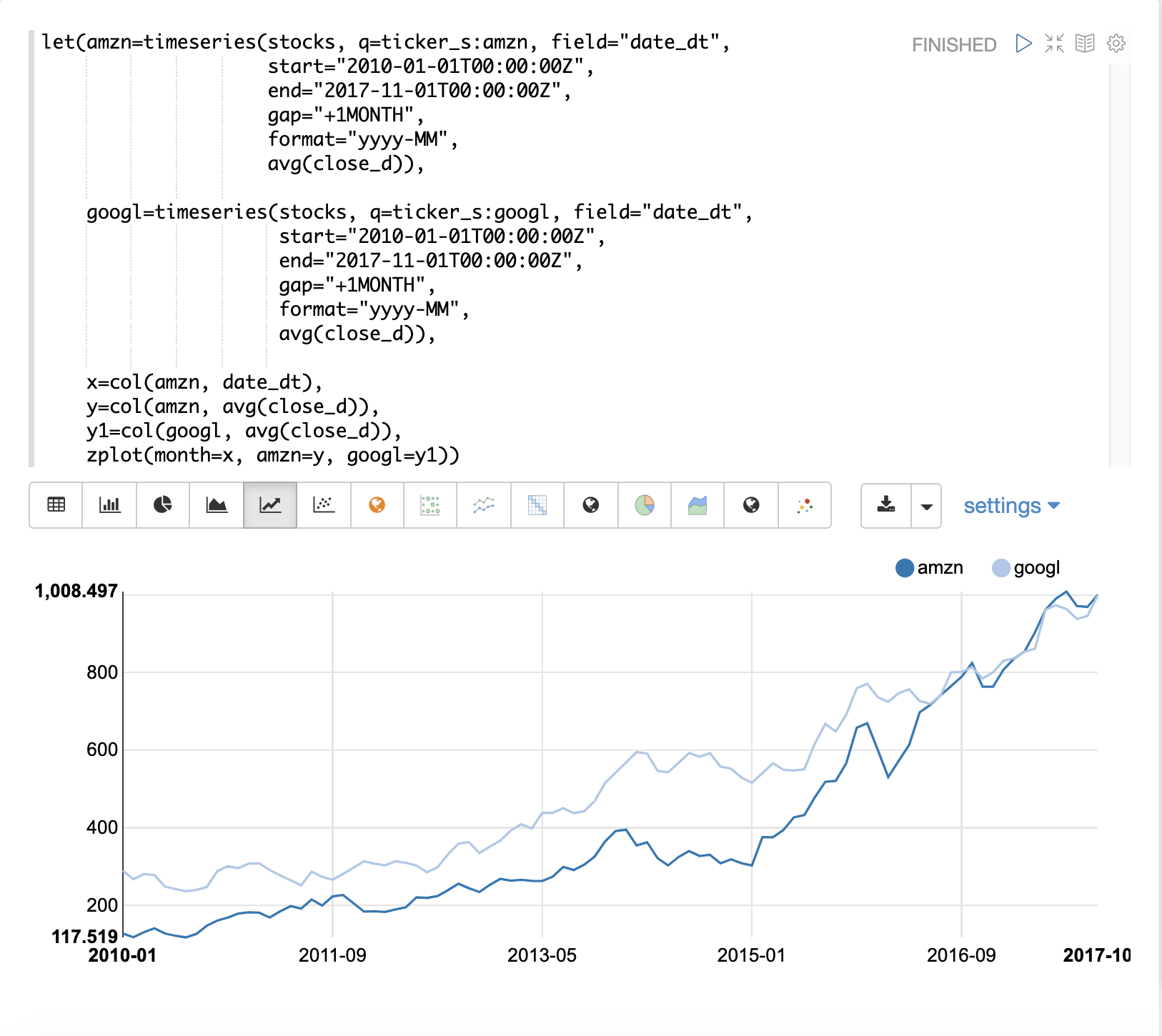
以下範例使用一階差分來使兩個時間序列達到平穩,如此一來它們便可以在沒有趨勢影響的情況下進行比較。
在這個範例中,我們將比較兩支股票:亞馬遜和 Google 的每月平均收盤價。下圖繪製了應用差分前的兩個時間序列。
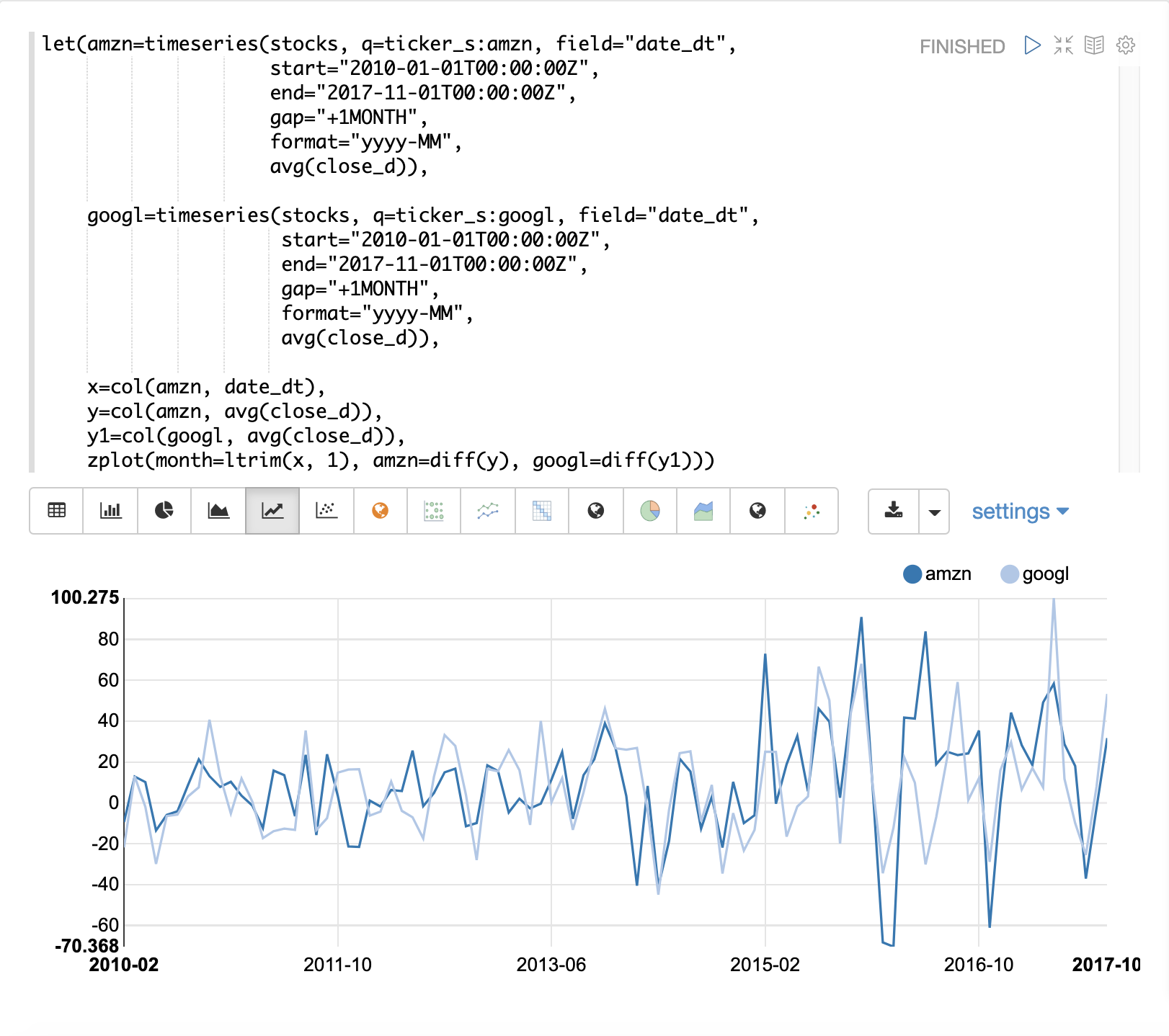
在下一個範例中,diff 函數會被套用至 zplot 函數內的兩個時間序列。diff 可以像 let 函數內的其他函數一樣,直接套用在 zplot 函數內。
請注意,現在兩個時間序列的趨勢都已去除,並且可以研究股票價格的每月變動,而不會受到趨勢的影響。
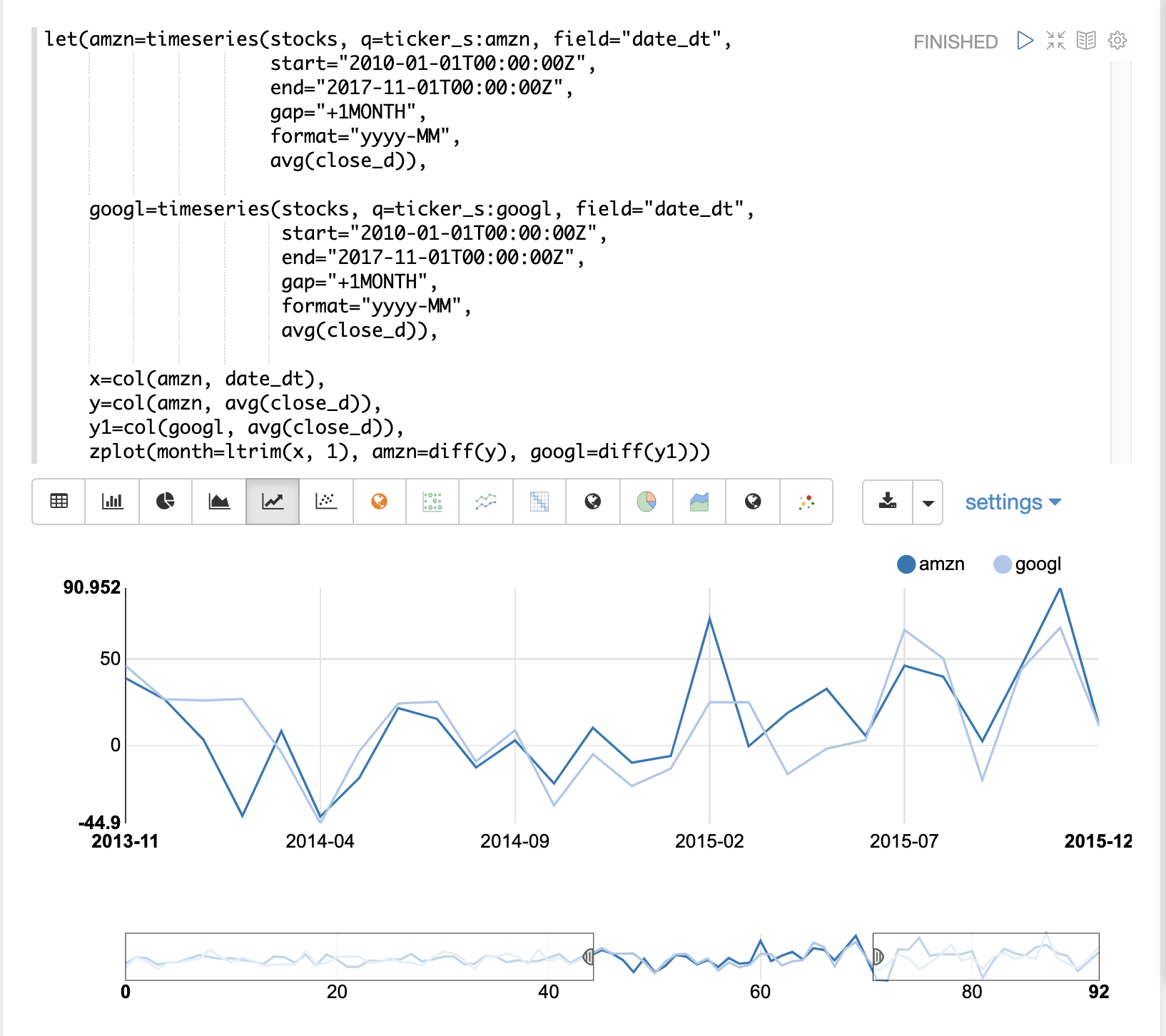
在下一個範例中,時間序列視覺化的 zoom 函數被用來放大到特定的月份範圍。這樣可以更仔細地檢查資料。仔細檢查資料後,似乎兩支股票的每月變動之間存在某種關聯。
在最後一個範例中,已差分的時間序列會使用 corr 函數進行關聯性分析。
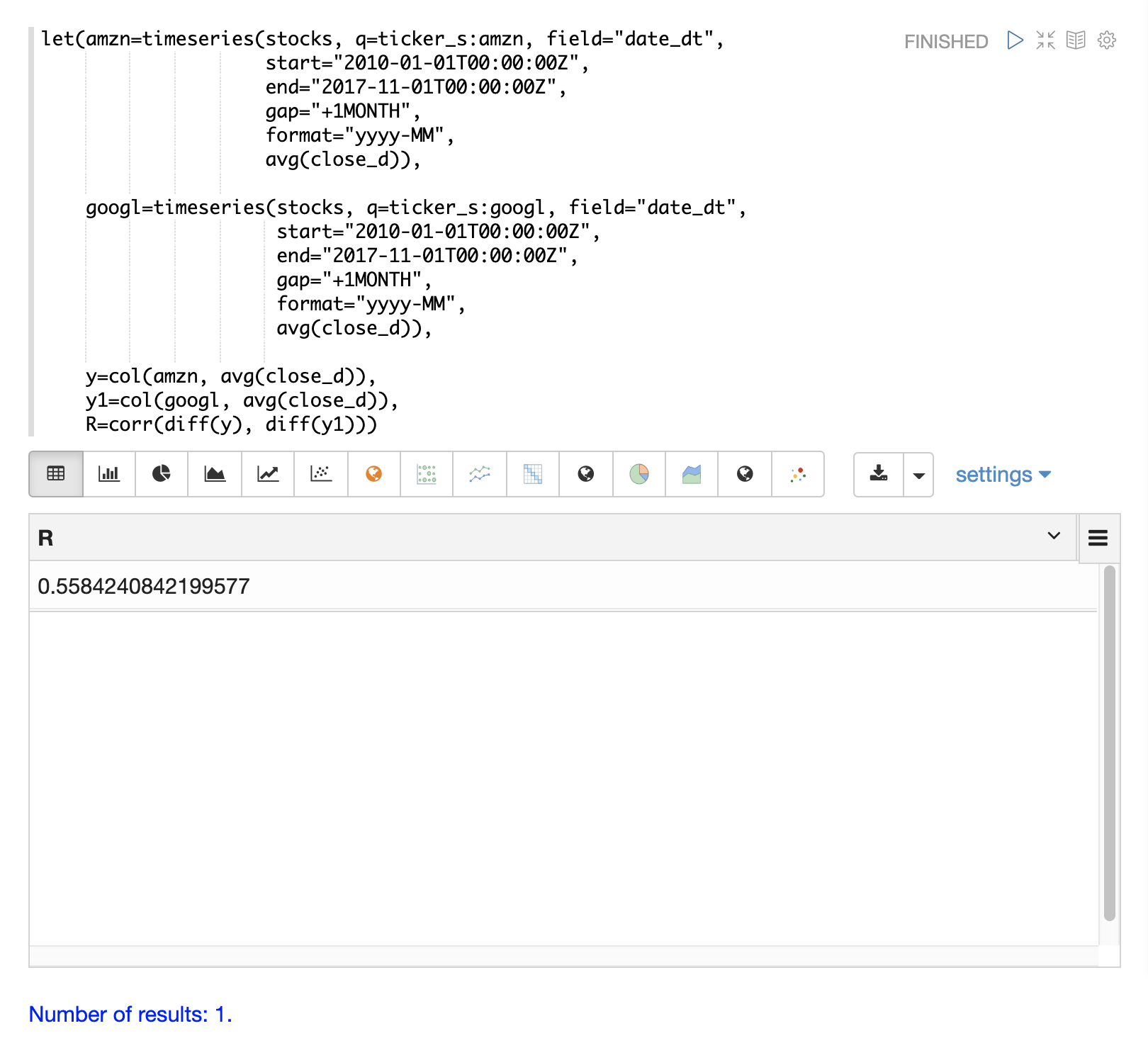
異常偵測
movingMAD(移動平均絕對偏差)函數可用於透過測量滑動視窗內的離散度(與平均值的偏差)來找出時間序列中的異常值。
movingMAD 函數的操作方式與移動平均類似,但它測量的是視窗內的平均絕對偏差,而不是平均值。透過尋找異常高或低的離散度,我們可以找出時間序列中的異常值。
在這個範例中,我們將使用亞馬遜兩年期間的每日股價。每日股票資料將提供更大的資料集進行研究。
在以下範例中,search 表達式用於回傳股票代碼為 AMZN 的兩年期間每日收盤價。
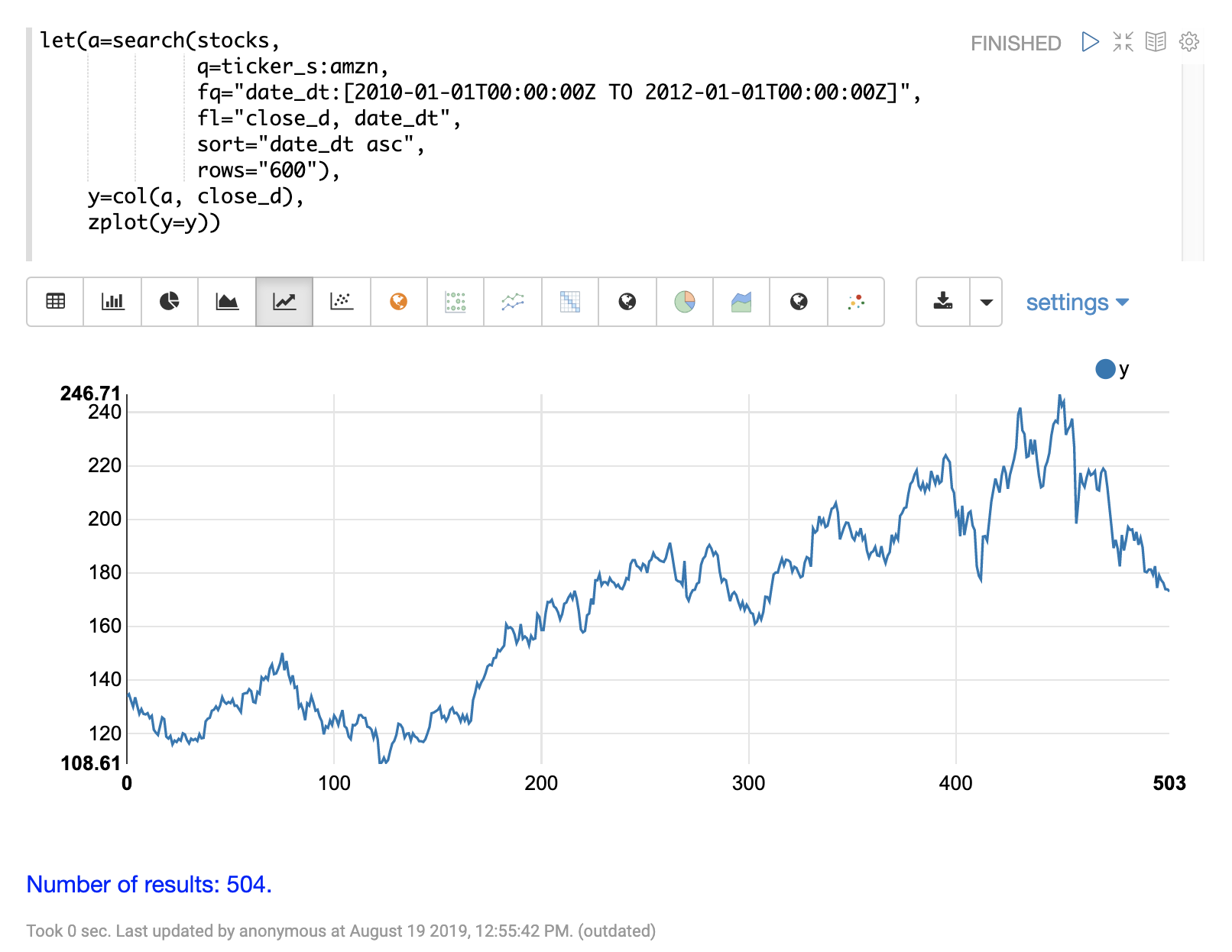
下一步是將 movingMAD 函數套用至資料,以計算 10 天視窗內的移動平均絕對偏差。以下範例顯示了如何套用和視覺化這個函數。
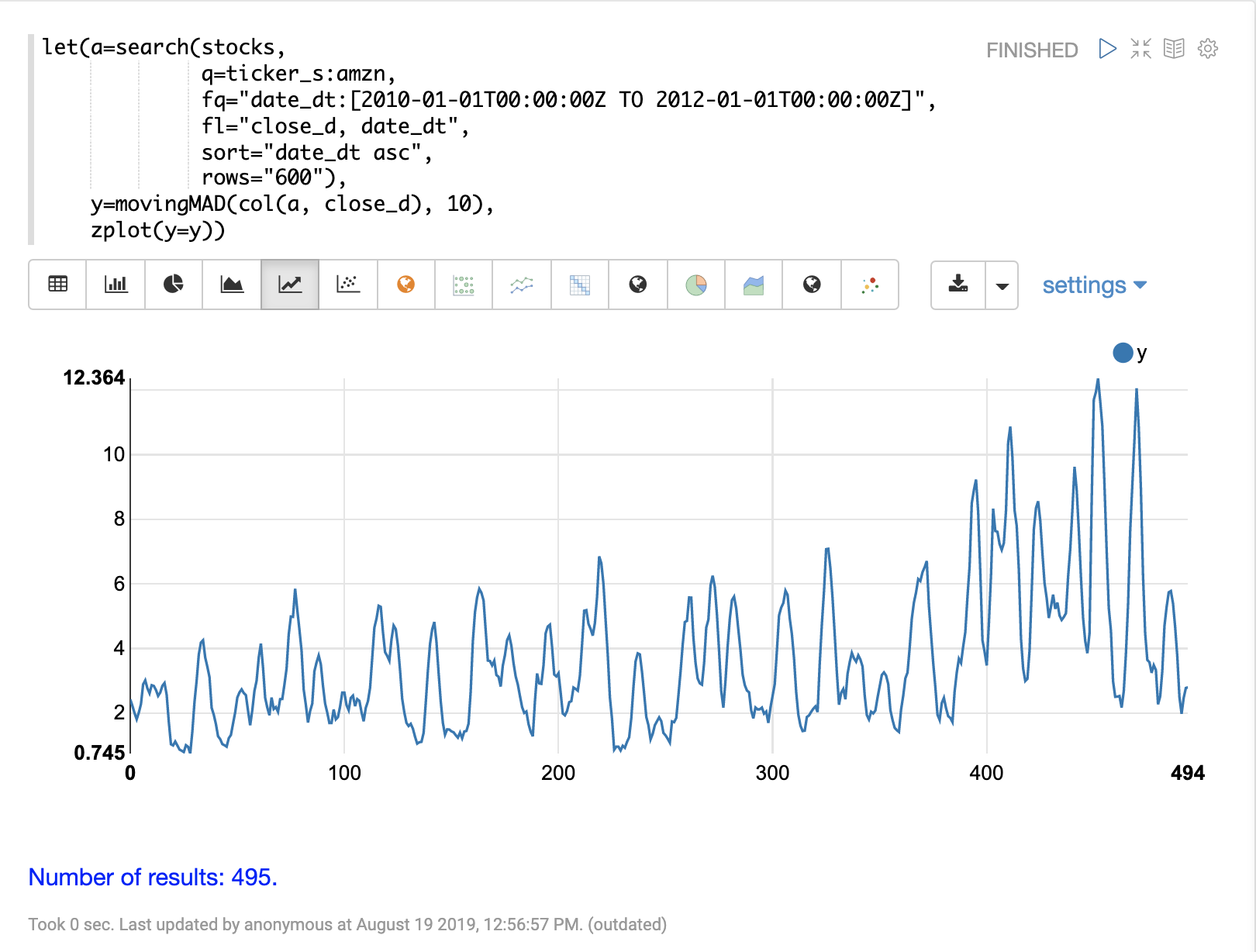
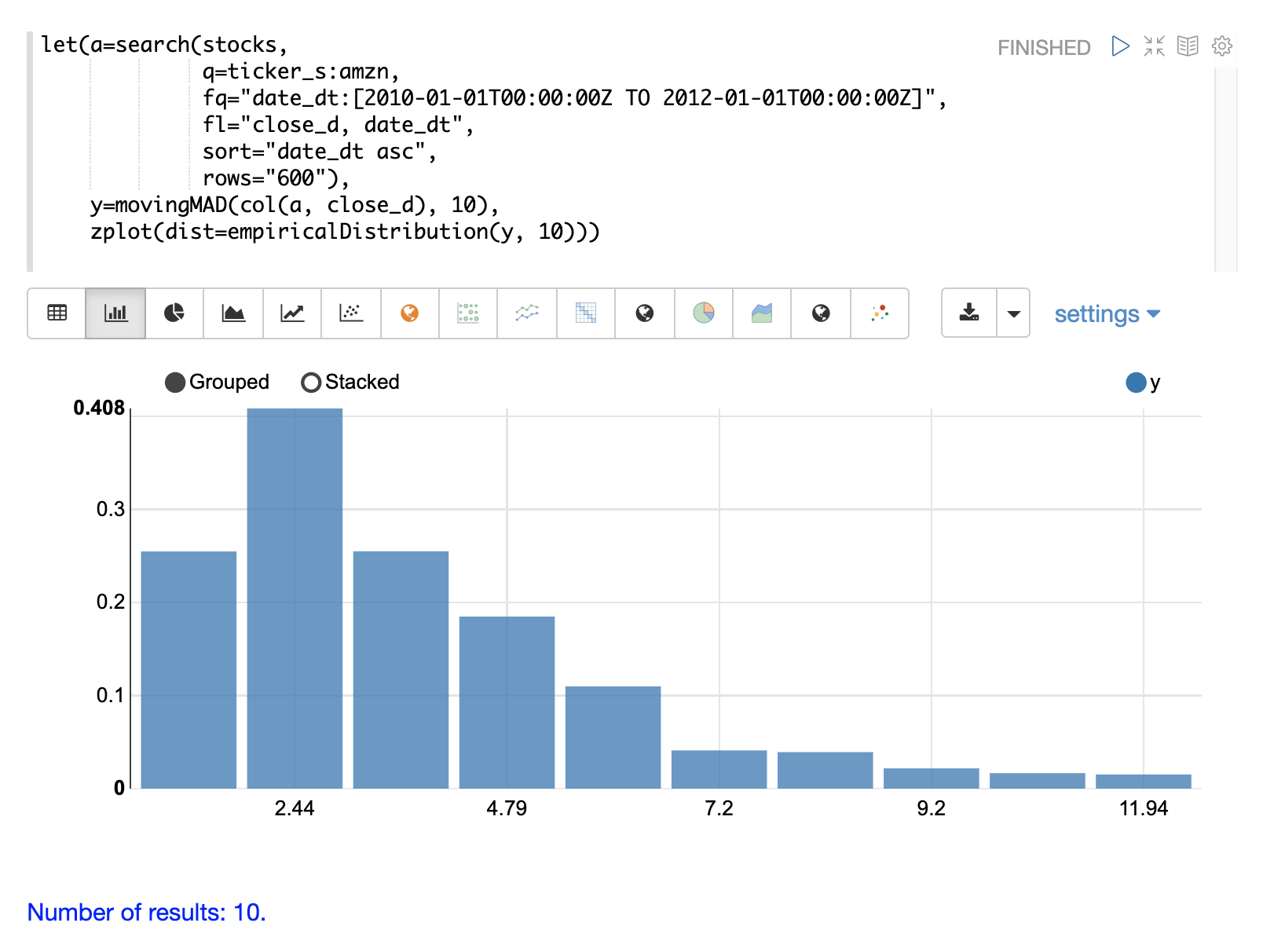
一旦計算出移動 MAD 後,我們可以使用 empiricalDistribution 函數來視覺化離散度的分佈。以下範例繪製了具有 10 個組距的經驗分佈,建立了一個時間序列離散度的 10 組距直方圖。
這個視覺化圖表顯示,大多數的平均絕對偏差都落在 0 到 9.2 之間,最後一個組距的平均值為 11.94。
最後一步是使用 outliers 函數偵測序列中的離群值。outliers 函數使用機率分佈來找出數值向量中的離群值。outliers 函數需要四個參數:
-
機率分佈
-
數值向量
-
低機率閾值
-
高機率閾值
-
從中選取數值向量的結果清單
outliers 函數會迭代數值向量,並使用機率分佈來計算每個值的累積分佈機率。如果累積分佈機率低於低機率閾值或高於高閾值,則會將該值視為離群值。當 outliers 函數遇到離群值時,會從第五個參數提供的結果清單中回傳對應的結果。它還會包含累積分佈機率和離群值的值。
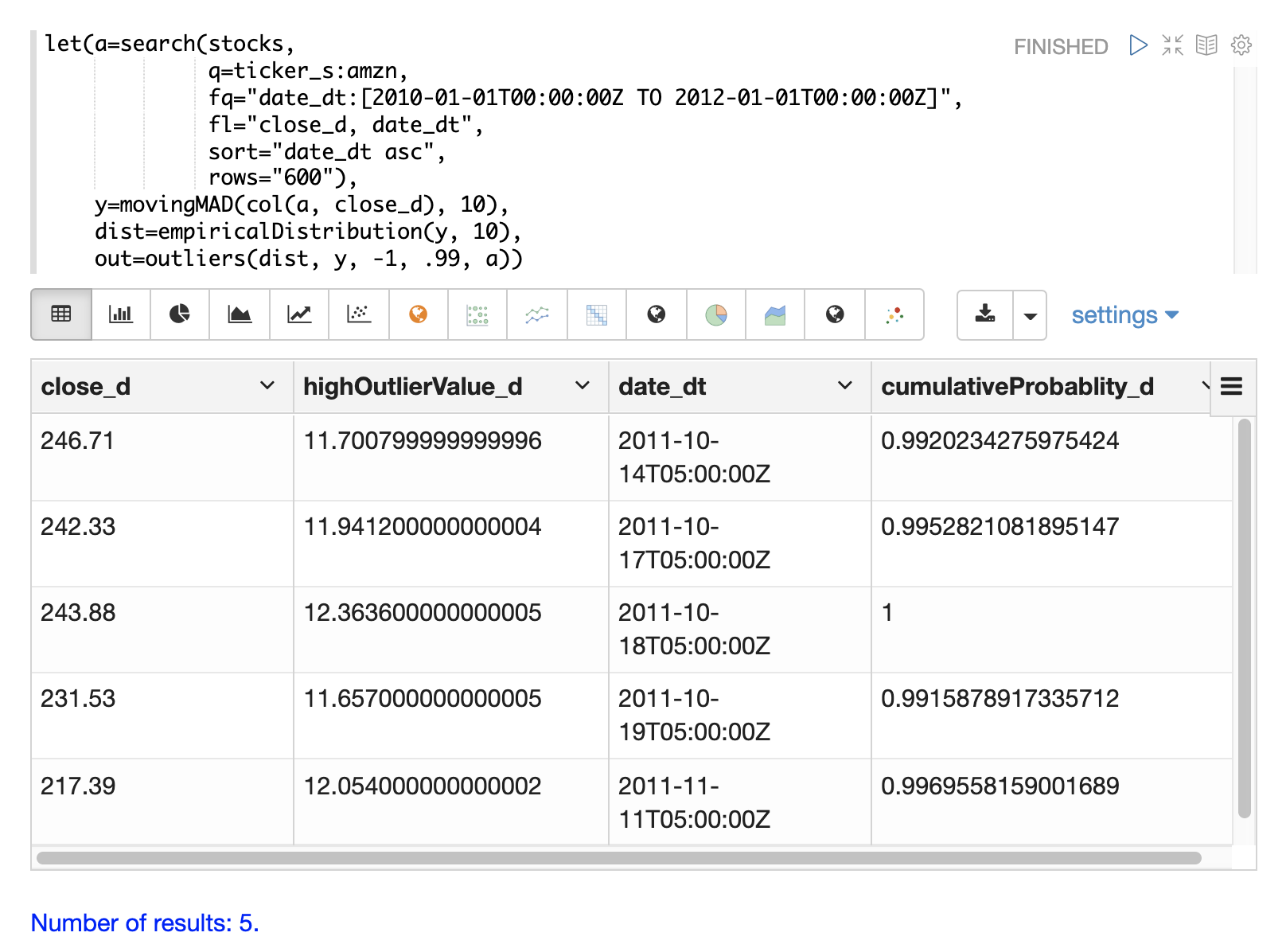
以下範例顯示了套用至亞馬遜股價資料集的 outliers 函數。移動平均絕對偏差的經驗分佈是第一個參數。包含移動平均絕對偏差的向量是第二個參數。-1 是低機率閾值,而 .99 是高機率閾值。-1 表示不會考慮低離群值。最後一個參數是包含 close_d 和 date_dt 欄位的原始結果集。
outliers 函數的輸出包含偵測到離群值的結果。在此情況下,偵測到 5 個高於 .99 機率閾值的結果。
建模
Solr 中支援的數學表達式包含許多可用於對時間序列進行建模的函數。這些函數包括線性迴歸、多項式和諧波曲線擬合、局部加權迴歸和 KNN 迴歸。
這些函數中的每一個都可以對時間序列進行建模,並用於內插(預測資料集內的值),其中一些函數還可以用於外插(預測超出資料集的值)。
線性迴歸、曲線擬合和機器學習章節的使用者指南中詳細介紹了各種迴歸函數。
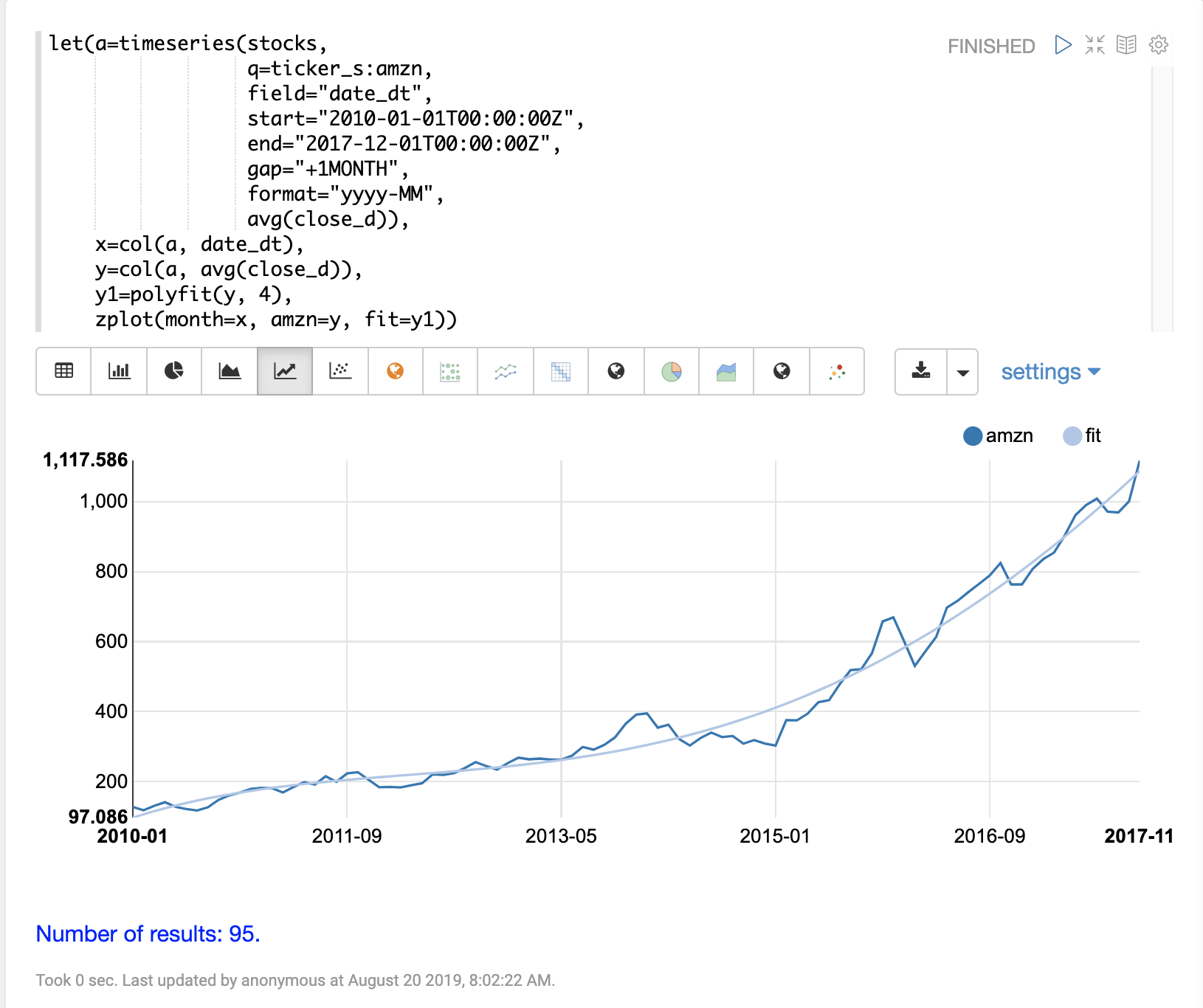
以下範例使用 polyfit 函數(多項式迴歸)來將非線性模型擬合到時間序列。所使用的資料集是亞馬遜八年期間的每月平均收盤價。
在這個範例中,polyfit 函數會回傳 y 軸的擬合模型,也就是使用 4 次多項式的每月平均收盤價。多項式的次數決定了模型中的曲線數量。擬合模型設定為變數 y1。然後使用 zplot 直接繪製擬合模型以及原始的 y 值。
視覺化圖表顯示了通過平均收盤價資料的平滑線擬合。
預測
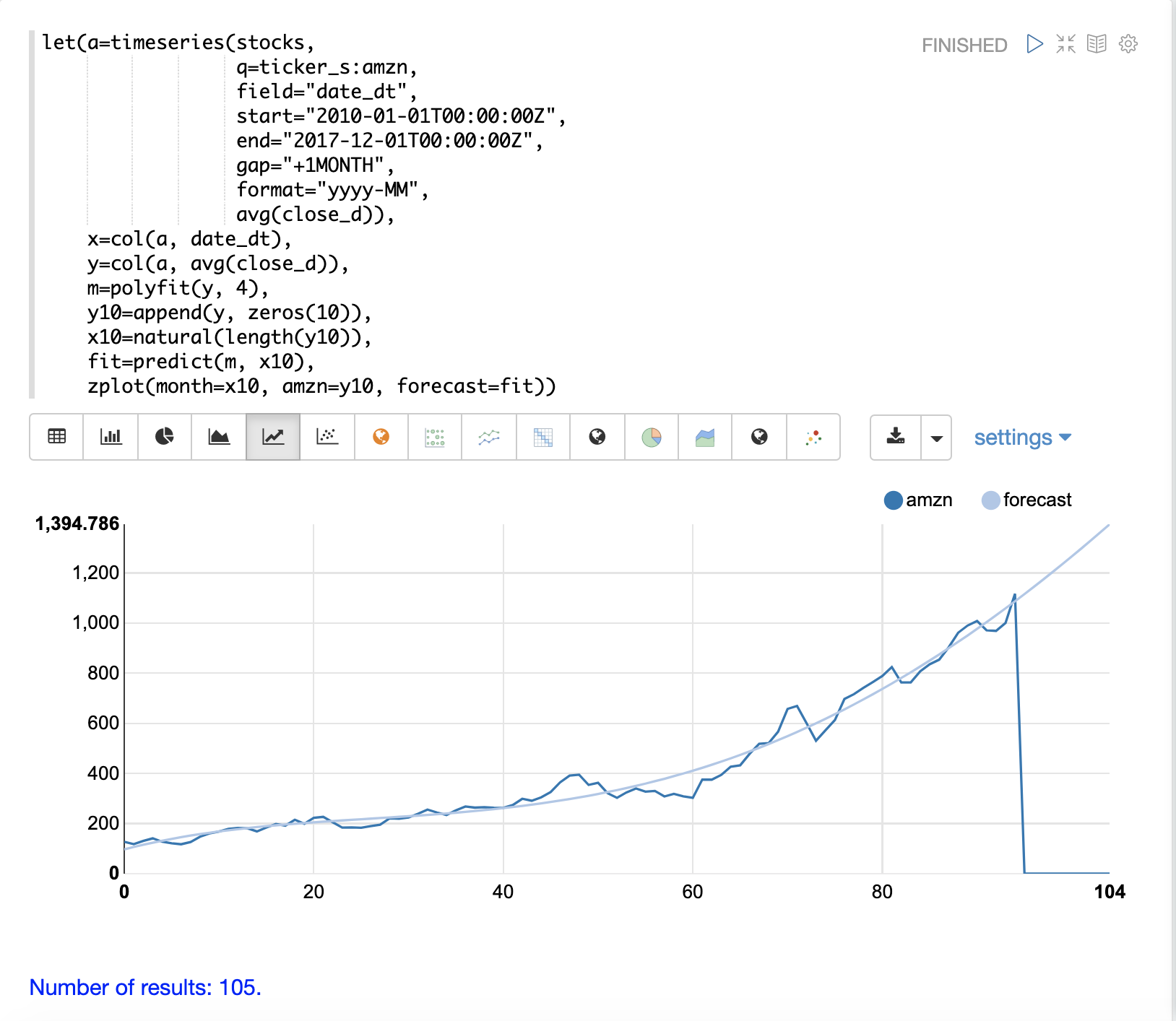
polyfit 函數也可以用來外推時間序列,以預測未來的股價。以下範例展示了 10 個月的預測。
在範例中,polyfit 函數將模型擬合至 y 軸,並且模型設定為變數 m。然後,為了建立預測,將 10 個零附加到 y 軸,以建立稱為 y10 的新向量。然後,使用 natural 函數建立新的 x 軸,該函數會回傳從 0 到 y10 長度的整數序列。新的 x 軸儲存在變數 x10 中。
predict 函數使用擬合模型來預測儲存在變數 x10 中的新 x 軸的值。
然後使用 zplot 函數在 x 軸上繪製 x10 向量,並在 y 軸上繪製 y10 向量和外推模型。請注意,y10 向量在觀察到的資料結束的地方降至零,但預測會沿著模型的擬合曲線繼續。