其他查詢解析器
除了主要的查詢解析器之外,還有其他幾個查詢解析器可以用來代替或與主要解析器結合使用,以達到特定的目的。
本節詳細介紹了其他解析器,並提供了如何使用它們的範例。
其中許多解析器的表達方式與本機參數相同。
區塊聯結查詢解析器
區塊聯結查詢解析器與巢狀文件一起使用,以查詢父文件和/或子文件。
這些解析器在區塊聯結查詢解析器一節中詳細介紹。
布林查詢解析器
BoolQParser 建立一個 Lucene BooleanQuery,它是其他查詢的布林組合。子查詢及其類型化的出現方式會指示文件如何被匹配和評分。
參數
must-
選用
預設值:無
一個查詢列表,這些查詢必須出現在相符的文件中並為評分做出貢獻。
must_not-
選用
預設值:無
一個查詢列表,這些查詢不得出現在相符的文件中。
should-
選用
預設值:無
一個查詢列表,這些查詢應該出現在相符的文件中。對於沒有
must查詢的 BooleanQuery,必須至少符合一個或多個should查詢,BooleanQuery 才會相符。 filter-
選用
預設值:無
一個查詢列表,這些查詢必須出現在相符的文件中。但是,與
must不同,篩選查詢的分數會被忽略。此外,這些查詢會快取在篩選快取中。若要避免快取,請新增cache=false作為本機參數,或將"cache":"false"屬性新增至底層的查詢 DSL 物件。 mm-
選用
預設值:
0必須符合的可選子句數量。預設情況下,匹配不需要任何可選子句(除非沒有必需子句)。如果設定此參數,則需要指定數量的
should子句。如果未設定此參數,則布林查詢的常用規則仍會在搜尋時套用 - 也就是說,不包含任何必要子句的布林查詢仍然必須符合至少一個可選子句。 excludeTags-
選用
預設值:無
以逗號分隔的標籤清單,用於排除上方參數中的查詢。請參閱以下說明。
範例
{!bool must=foo must=bar}{!bool filter=foo should=bar}{!bool should=foo should=bar should=qux mm=2}參數也可能是多值參考。上述先前的範例等同於
q={!bool must=$ref}&ref=foo&ref=bar可以透過標籤排除參考的查詢。總體而言,此概念與分面中的排除 fq類似。
q={!bool must=$ref excludeTags=t2}&ref={!tag=t1}foo&ref={!tag=t2}bar由於後面的查詢透過 t2 被排除,因此產生的查詢等同於
q={!bool must=foo}Boost 查詢解析器
BoostQParser 擴展了 QParserPlugin,並從輸入值建立一個加權查詢。主要值是要「包裝」和「加權」的任何查詢——只有符合該查詢的文件才會符合此解析器產生的最終查詢。參數 b 是一個函式,將針對符合原始查詢的每個文件進行評估,函式的結果將會乘入該文件的最終分數中。
加權查詢解析器範例
建立查詢 name:foo,該查詢由函式查詢 log(popularity) 加權(分數相乘)
q={!boost b=log(popularity)}name:foo建立查詢 name:foo,其分數乘以數值欄位 price 的倒數——有效地透過降低最終分數來「降級」具有高 price 的文件
// NOTE: we "add 1" to the denominator to prevent divide by zero
q={!boost b=div(1,add(1,price))}name:foo對於您希望將符合主要查詢的每個文件的分數,乘以該文件從另一個查詢獲得的分數的情況,query(…) 函式特別有用。
此範例使用本機參數變數,建立 name:foo 的查詢,該查詢由獨立指定的查詢 category:electronics 的分數加權
q={!boost b=query($my_boost)}name:foo
my_boost=category:electronics摺疊查詢解析器
當結果集中不同群組的數量很高時,CollapsingQParser 實際上是一個後置篩選器,它比 Solr 的標準方法提供效能更高的欄位摺疊。
此解析器會在將結果集轉發到其餘的搜尋元件之前,將結果集摺疊為每個群組單一文件。因此,所有下游元件(分面、醒目提示等)都將使用摺疊的結果集。
有關使用 CollapsingQParser 的詳細資訊,請參閱摺疊和展開結果章節。
複雜片語查詢解析器
ComplexPhraseQParser 支援在片語查詢中使用萬用字元、OR 等,使用 Lucene 的 ComplexPhraseQueryParser。
在底層,此查詢解析器使用 Span 群組的查詢,例如 spanNear、spanOr 等,並受限於該解析器系列的相同限制。
參數
inOrder-
選用
預設值:
true設定為
true以強制片語查詢依照指定的順序比對詞彙。 df-
選用
預設值:無
預設的搜尋欄位。
範例
{!complexphrase inOrder=true}name:"Jo* Smith"{!complexphrase inOrder=false}name:"(john jon jonathan~) peters*"混合使用排序和未排序的複雜片語查詢
+_query_:"{!complexphrase inOrder=true}manu:\"a* c*\"" +_query_:"{!complexphrase inOrder=false df=name}\"bla* pla*\""複雜片語解析器限制
效能對與模式相關聯的唯一詞彙數量很敏感。例如,搜尋「a*」將會為索引中指示欄位中,以單字母「a」開頭的所有詞彙建立一個大型的 OR 子句(技術上是具有許多詞彙的 SpanOr)。將萬用字元限制為至少兩個或最好三個字母作為前綴可能是明智之舉。允許非常短的前綴可能會導致傳回過多低品質的文件。
請注意,它也支援開頭萬用字元「*a」,但會產生效能上的影響。在索引時分析中應用 ReversedWildcardFilterFactory 通常是一個好主意。
查詢設定和複雜片語解析器
由於上述的查詢擴展,此解析器可能會產生違反幾個 solrconfig.xml 設定的查詢。
特別相關的是 maxBooleanClauses 和 minPrefixLength,這是 Solr 為了遏制過於耗費資源的查詢而提供的兩個保護措施。
<maxBooleanClauses>4096</maxBooleanClauses>
<minPrefixLength>1</minPrefixLength>這兩個屬性在查詢大小調整和預熱章節中有更詳細的描述。管理員在進行變更以支援「複雜片語」查詢時,應仔細考量效能的權衡。
複雜片語解析器的停用詞
不建議將停用詞消除與此查詢解析器一起使用。
假設我們將詞彙 the、up 和 to 新增到集合的 stopwords.txt,並在名為「features」的欄位中,為包含文字「Stores up to 15,000 songs, 2500 photos, or 150 yours of video」的文件建立索引。
雖然下面的查詢未使用此解析器
q=features:"Stores up to 15,000"但會傳回該文件。下一個確實使用複雜片語查詢解析器的查詢,如下面的查詢所示
q=features:"sto* up to 15*"&defType=complexphrase不會傳回該文件,因為 SpanNearQuery 沒有辦法以類似 PhraseQuery 的方式處理停用詞。如果您的使用案例必須移除停用詞,請使用自訂篩選器工廠,或者可能使用自訂的同義詞篩選器,將指定的停用詞縮減為一些不可能的權杖。
欄位查詢解析器
FieldQParser 擴展了 QParserPlugin,並從輸入值建立欄位查詢,適當地套用文字分析並建構片語查詢。參數 f 是要查詢的欄位。
範例
{!field f=myfield}Foo Bar此範例建立一個片語查詢,其中包含「foo」,後面跟著「bar」(假設 myfield 的分析器是一個文字欄位,該分析器會依據空格和文字小寫來分割)。這通常等同於 Lucene 查詢解析器表達式 myfield:"Foo Bar"。
篩選器查詢解析器
語法為
q={!filters param=$fqs excludeTags=sample}field:text&
fqs=COLOR:Red&
fqs=SIZE:XL&
fqs={!tag=sample}BRAND:Foo
這等同於
q=+field:text +COLOR:Red +SIZE:XL
param 本機參數使用「$」語法來引用幾個查詢,其中 excludeTags 可能會省略其中一些查詢。
函式查詢解析器
FunctionQParser 擴展了 QParserPlugin,並從輸入值建立函式查詢。這只是在 Solr 中使用函式查詢的一種方式;對於另一種更整合的方法,請參閱函式查詢章節。
範例
{!func}log(foo)函式範圍查詢解析器
FunctionRangeQParser 擴展了 QParserPlugin,並在函式上建立範圍查詢。這也稱為 frange,如下面的範例所示。
參數
l-
選用
預設值:無
下限。
u-
選用
預設值:無
上限。
incl-
選用
預設值:
true包含下限。
incu-
選用
預設值:
true包含上限。
範例
{!frange l=1000 u=50000}myfield fq={!frange l=0 u=2.2} sum(user_ranking,editor_ranking)這兩個範例都透過在宣告的欄位或函式查詢中找到的值範圍來限制結果。在第二個範例中,我們正在進行總和計算,然後定義只有介於 0 和 2.2 之間的值才會傳回給使用者。
如需有關函式範圍查詢的詳細資訊,請參閱 Yonik Seeley 的介紹性部落格文章 Solr 1.4 中函式的範圍。
圖形查詢解析器
graph 查詢解析器會對從包裝查詢所識別的起始根文件集「可到達」的所有文件,執行廣度優先的週期感知圖形遍歷。
該圖形是根據文件之間的連結所建立,連結是基於您指定為查詢一部分的 from 和 to 欄位中找到的詞彙。
支援的欄位類型是啟用 docValues 的點欄位,或具有 indexed=true 或 docValues=true 的字串欄位。
對於 indexed=false 和 docValues=true 的字串欄位,請參閱 SortedDocValuesField.newSlowSetQuery() 的 javadoc,以了解其效能特性,因此 indexed=true 對於大多數使用案例來說效能會更好。 |
圖形查詢參數
to-
選用
預設值:
edge_ids要檢查以識別圖形遍歷之輸出邊緣的相符文件欄位名稱。
from-
選用
預設值:
node_id要檢查以識別輸入圖形邊緣的候選文件欄位名稱。
traversalFilter-
選用
預設值:無
可以提供可選查詢來限制遍歷的文件範圍。
maxDepth-
選用
預設值:
-1(無限)整數,指定從初始查詢開始,圖形的廣度優先搜尋應深入多少層。
returnRoot-
選用
預設值:
true布林值,指示是否應將符合原始查詢的文件(以定義圖形的起點)包含在最終結果中。
returnOnlyLeaf-
選用
預設值:
false布林值,指示是否應篩選查詢結果,以便僅傳回沒有輸出邊緣的文件。
useAutn-
選用
預設值:
false布林值,指示是否應為廣度優先搜尋的每次迭代編譯自動機,這對於某些圖形來說可能更快。
圖形查詢範例
為了了解圖形解析器的工作方式,請考慮以下包含 8 個節點(A 到 H)和 9 個邊緣(1 到 9)的有向循環圖
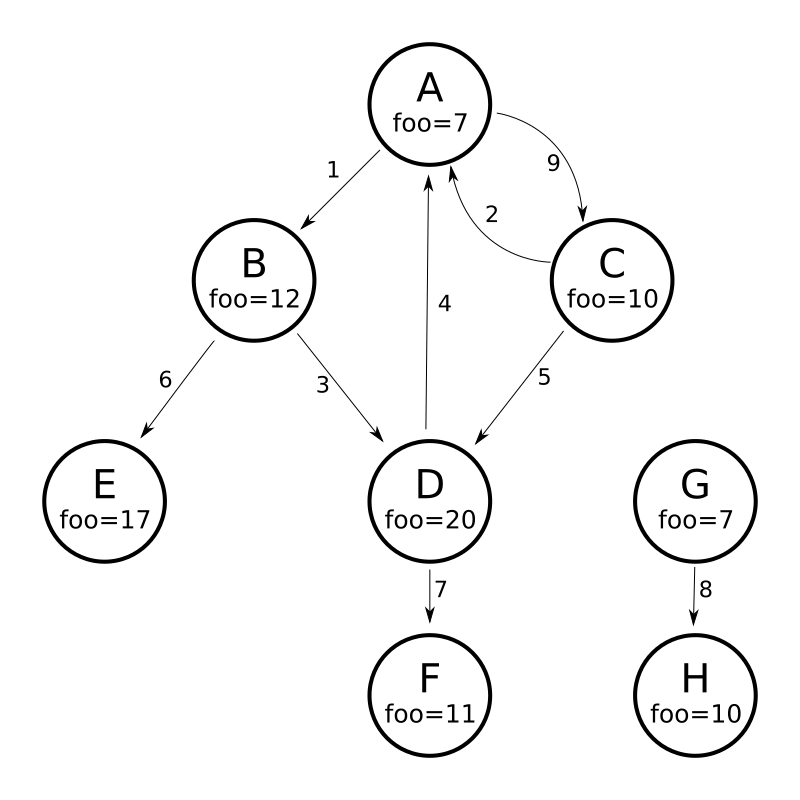
將此圖形建模為 Solr 文件的一種方法是,為每個節點建立一個文件,其中包含識別每個節點的輸入和輸出邊緣的多值欄位
curl -H 'Content-Type: application/json' 'https://127.0.0.1:8983/solr/my_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["1","9"], "in_edge":["4","2"] },
{"id":"B","foo": 12, "out_edge":["3","6"], "in_edge":["1"] },
{"id":"C","foo": 10, "out_edge":["5","2"], "in_edge":["9"] },
{"id":"D","foo": 20, "out_edge":["4","7"], "in_edge":["3","5"] },
{"id":"E","foo": 17, "out_edge":[], "in_edge":["6"] },
{"id":"F","foo": 11, "out_edge":[], "in_edge":["7"] },
{"id":"G","foo": 7, "out_edge":["8"], "in_edge":[] },
{"id":"H","foo": 10, "out_edge":[], "in_edge":["8"] }
]'使用上面顯示的模型,以下查詢示範從節點 A 可到達的所有節點的簡單遍歷
https://127.0.0.1:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge}id:A"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"E" },
{ "id":"F" } ]
}我們也可以使用 traversalFilter 將圖形遍歷限制為僅限於 foo 欄位中最大值為 15 的節點。在這種情況下,這表示排除 D、E 和 F——F 的值為 foo=11,但因為遍歷跳過了 D,所以無法到達 F
https://127.0.0.1:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+traversalFilter='foo:[*+TO+15]'}id:A...
"response":{"numFound":3,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" } ]
}到目前為止所顯示的範例都使用單一文件("id:A")的查詢作為圖形遍歷的根節點,但可以使用任何查詢來識別要用作根節點的多個文件。下一個範例示範如何使用 maxDepth 參數來尋找與 foo 欄位中小於或等於 10 的根節點最多相隔一條邊緣的所有節點
https://127.0.0.1:8983/solr/my_graph/query?fl=id&q={!graph+from=in_edge+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}簡化的模型
為了協助示範「from」和「to」參數的確切運作方式,並讓您了解可能的情況,上述範例中使用的文件和欄位建模明確地列舉了每個節點的所有輸出和輸入邊緣。透過多組用於識別輸入和輸出邊緣的欄位,可以對包含集合中部分或全部文件的許多獨立有向圖進行建模。
但在許多情況下,也可以大幅簡化所使用的模型。
例如,上圖中顯示的相同圖形可以由代表每個節點且只知道其連結節點 ID 的 Solr 文件建模,而不知道任何有關輸入連結的資訊
curl -H 'Content-Type: application/json' 'https://127.0.0.1:8983/solr/alt_graph/update?commit=true' --data-binary '[
{"id":"A","foo": 7, "out_edge":["B","C"] },
{"id":"B","foo": 12, "out_edge":["E","D"] },
{"id":"C","foo": 10, "out_edge":["A","D"] },
{"id":"D","foo": 20, "out_edge":["A","F"] },
{"id":"E","foo": 17, "out_edge":[] },
{"id":"F","foo": 11, "out_edge":[] },
{"id":"G","foo": 7, "out_edge":["H"] },
{"id":"H","foo": 10, "out_edge":[] }
]'使用這種替代文件模型,只需將「from」參數變更為以「id」欄位取代「in_edge」欄位,仍然可以執行上述所有相同的查詢
https://127.0.0.1:8983/solr/alt_graph/query?fl=id&q={!graph+from=id+to=out_edge+maxDepth=1}foo:[*+TO+10]...
"response":{"numFound":6,"start":0,"docs":[
{ "id":"A" },
{ "id":"B" },
{ "id":"C" },
{ "id":"D" },
{ "id":"G" },
{ "id":"H" } ]
}雜湊範圍查詢解析器
雜湊範圍查詢解析器會返回欄位中包含的值經過雜湊處理後會落在特定範圍內的文件。當使用 method=crossCollection 時,聯結查詢解析器會使用此解析器。雜湊範圍查詢解析器對於每個此查詢解析器將操作的欄位,都有一個單獨的區段快取。
當使用雜湊範圍查詢解析器指定最小/最大雜湊範圍和欄位名稱時,只會返回包含的欄位值雜湊到該範圍的文件。 如果您想要查詢非常大的結果集,您可以查詢不同的雜湊範圍,以便在每個範圍請求中返回一部分的文件。
在跨集合聯結的情況下,雜湊範圍查詢解析器用於確保每個分片只取得會落在該分片上的聯結鍵集合。
此查詢解析器使用 MurmurHash3_x86_32。這與 Solr 中預設複合 ID 路由器的預設雜湊相同。
聯結查詢解析器
聯結查詢解析器允許使用者執行查詢,以正規化文件之間的關係,類似於 SQL 風格的聯結。
此查詢解析器的詳細資訊位於聯結查詢解析器一節中。
學習排序查詢解析器
LTRQParserPlugin 是一個特殊的解析器,用於使用基於機器學習模型的更複雜的排序查詢,重新排序簡單查詢的前幾項結果。
範例
{!ltr model=myModel reRankDocs=100}關於使用 LTRQParserPlugin 的詳細資訊,可以在學習排序一節中找到。
最大分數查詢解析器
MaxScoreQParser 擴展了 LuceneQParser,但會從子句返回最大分數。 它通過將所有 SHOULD 子句包裝在 DisjunctionMaxQuery 中,並且 tie=1.0 來實現此目的。任何 MUST 或 PROHIBITED 子句都會按原樣傳遞。非布林查詢,例如 NumericRange,會回退到 LuceneQParser 解析器的行為。
範例
{!maxscore tie=0.01}C OR (D AND E)MinHash 查詢解析器
MinHashQParser 為使用 MinHashFilterFactory 分析的欄位建立查詢。 查詢會測量查詢字串和 MinHash 欄位之間的 Jaccard 相似度;如果需要,允許更快、近似的匹配。 解析器支援兩種操作模式。第一種是在正常分析時從文字產生符號;第二種是提供明確的符號。
目前,查詢傳回的分數反映了符合條件的頂層元素數量,並且 **未** 在 0 和 1 之間正規化。
sim-
必要
預設值:無
最小相似度。預設行為是尋找任何大於零的相似度。介於
0.0和1.0之間的數值。 tp-
選用
預設值:
1.0所需的真陽性率。對於小於
1.0的值,可以使用經過最佳化且速度更快的頻帶查詢。頻帶行為取決於所要求的sim和tp值。 field-
選用
預設值:無
MinHash 值編入索引的欄位。此欄位通常用於分析提供給查詢解析器的文字。它也用於查詢欄位。
sep-
選用
預設值:" " (空字串)
分隔符號字串。如果提供了非空的分隔符號字串,則查詢字串會被解釋為由分隔符號字串分隔的預先分析的值清單。在這種情況下,不會對字串執行其他分析:符號會按原樣使用。
analyzer_field-
選用
預設值:無
此參數可用於定義文字的分析方式,與查詢欄位不同。 它用於在使用預先分析的字串
field來儲存 MinHash 值時分析查詢文字。 請參閱下面的範例。
此查詢解析器已註冊,名稱為 min_hash。
具有分析欄位的範例
典型分析
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>
...
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false" />在此,輸入文字會以空白分隔,符號會正規化,產生的符號串流會組合成所有 5 個字的字詞組串流,然後進行雜湊處理。保留來自每個 512 個儲存桶的最低雜湊值,並產生為輸出符號。
對此欄位的查詢至少需要產生一個字詞組,因此需要 5 個不同的符號。
範例查詢
{!min_hash field="min_hash_analysed"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5"}At least five or more tokens
{!min_hash field="min_hash_analysed" sim="0.5" tp="0.5"}At least five or more tokens具有預先分析欄位的範例
在此,MinHash 是預先計算的,最有可能使用 Lucene 分析內嵌進行計算,如下所示。從架構中取得分析器會更謹慎。
ICUTokenizerFactory factory = new ICUTokenizerFactory(Collections.EMPTY_MAP);
factory.inform(null);
Tokenizer tokenizer = factory.create();
tokenizer.setReader(new StringReader(text));
ICUFoldingFilterFactory filter = new ICUFoldingFilterFactory(Collections.EMPTY_MAP);
TokenStream ts = filter.create(tokenizer);
HashMap<String, String> args = new HashMap<>();
args.put("minShingleSize", "5");
args.put("outputUnigrams", "false");
args.put("outputUnigramsIfNoShingles", "false");
args.put("maxShingleSize", "5");
args.put("tokenSeparator", " ");
ShingleFilterFactory sff = new ShingleFilterFactory(args);
ts = sff.create(ts);
HashMap<String, String> args2 = new HashMap<>();
args2.put("bucketCount", "512");
args2.put("hashSetSize", "1");
args2.put("hashCount", "1");
MinHashFilterFactory mhff = new MinHashFilterFactory(args2);
ts = mhff.create(ts);
CharTermAttribute termAttribute = ts.getAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken())
{
char[] buff = termAttribute.buffer();
...
}
ts.end();架構只會定義一個多值的字串值和一個可選的欄位,以便在分析時使用 - 類似於上述情況。
<field name="min_hash_string" type="strings" multiValued="true" indexed="true" stored="true"/>
<!-- Optional -->
<field name="min_hash_analysed" type="text_min_hash" multiValued="false" indexed="true" stored="false"/>
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" multiValued="true"/>
<!-- Optional -->
<fieldType name="text_min_hash" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ICUTokenizerFactory"/>
<filter class="solr.ICUFoldingFilterFactory"/>
<filter class="solr.ShingleFilterFactory" minShingleSize="5" outputUnigrams="false" outputUnigramsIfNoShingles="false" maxShingleSize="5" tokenSeparator=" "/>
<filter class="org.apache.lucene.analysis.minhash.MinHashFilterFactory" bucketCount="512" hashSetSize="1" hashCount="1"/>
</analyzer>
</fieldType>範例查詢
{!min_hash field="min_hash_string" sep=","}HASH1,HASH2,HASH3
{!min_hash field="min_hash_string" sim="0.9" analyzer_field="min_hash_analysed"}Lets hope the config and code for analysis are in sync也可以使用已知的雜湊來查詢分析欄位(與上述相反)
{!min_hash field="min_hash_analysed" analyzer_field="min_hash_string" sep=","}HASH1,HASH2,HASH3預先分析的欄位表示可以針對每個文件復原雜湊值,而不是重新雜湊。 初始查詢階段傳回儲存的 minhash 欄位之後,可以接著使用 min_hash 查詢來尋找類似的文件。
頻帶查詢
在上述設定中,查詢解析器的預設行為是產生布林查詢,並將 512 個常數分數詞彙查詢 OR 在一起:每個雜湊一個。在這種情況下,如果一個雜湊值符合,則產生分數 1,如果所有雜湊值都符合,則產生分數 512。
頻帶查詢混合了結合和分離。我們可以有 256 個頻帶,每個頻帶都有兩個查詢 AND 在一起,128 個頻帶有 4 個雜湊值 AND 在一起,依此類推。頻帶越少,查詢效能越高,但我們可能會遺漏一些符合的項目。速度和精確度之間需要權衡。使用 64 個頻帶,分數範圍將從 0 到 64(OR 在一起的頻帶數量)
在給定的所需相似度和可接受的真陽性率下,查詢解析器會計算適當的頻帶大小[1]。 它會尋找滿足以下條件的最小頻帶數量
如果沒有足夠的雜湊值來填滿查詢的最終頻帶,它會環繞到開頭。
延伸閱讀
如需一般介紹,請參閱「巨量資料探勘」[1]。
對於 ~1500 個字的文件,預期索引大小額外負擔約為 ~10%;您的結果可能會有所不同。 預期 512 個雜湊值能很好地表示 ~2500 個字。
在最初的論文[2]中提出了使用一組 MinHash 值,但提供了 Jaccard 相似度的偏差估計。 在某些情況下,該偏差可能是一件好事。輪換和簡短的文件也是如此。 實作衍生自後續工作[3]中提出的無偏差方法。
[1] Leskovec, Jure; Rajaraman, Anand & Ullman, Jeffrey D. "Mining of Massive Datasets", Cambridge University Press; 2nd edition (December 29, 2014), Chapter 3, ISBN: 9781107077232.
[2] Broder, Andrei Z. (1997), "On the resemblance and containment of documents", Compression and Complexity of Sequences: Proceedings, Positano, Amalfitan Coast, Salerno, Italy, June 11-13, 1997 (PDF), IEEE, pp. 21–29, doi:10.1109/SEQUEN.1997.666900.
[3] Shrivastava, Anshumali & Li, Ping (2014), "Improved Densification of One Permutation Hashing", 30th Conference on Uncertainty in Artificial Intelligence (UAI), Quebec City, Quebec, Canada, July 23-27, 2014, AUAI, pp. 225-234, http://www.auai.org/uai2014/proceedings/individuals/225.pdf
更多相似查詢解析器
MLTQParser 可以擷取與給定文件相似的文件。它使用 Lucene 現有的 MoreLikeThis 邏輯,並且也可以在 SolrCloud 模式下運作。關於如何使用此查詢解析器的資訊,請參閱有關「更多相似」的文件,位於「更多相似」查詢解析器一節中。
巢狀查詢解析器
NestedParser 擴展了 QParserPlugin 並建立巢狀查詢,並可以透過本機參數重新定義其類型。這在設定中指定預設值並讓用戶端間接參考它們時非常有用。
範例
{!query defType=func v=$q1}如果 q1 參數是 price,則查詢會是對 price 欄位的函數查詢。如果 q1 參數是 \{!lucene}inStock:true}},則會從符合 inStock=true 的文件的 Lucene 語法字串建立詞彙查詢。這些參數會在 solrconfig.xml 的 defaults 區段中定義。
<lst name="defaults">
<str name="q1">{!lucene}inStock:true</str>
</lst>如需有關巢狀查詢可能性的更多資訊,請參閱 Yonik Seeley 的部落格文章Solr 中的巢狀查詢。
酬載查詢解析器
這些查詢解析器會利用在編製索引期間編碼在詞彙上的酬載。 可以使用 DelimitedPayloadTokenFilter 或 NumericPayloadTokenFilter 在詞彙上編碼酬載。
酬載分數解析器
PayloadScoreQParser 將每個符合詞彙的數值(整數或浮點數)酬載併入分數中。 主要查詢會從欄位類型的查詢分析剖析到 SpanQuery 中,這基於以下 operator 參數的值。
此解析器接受以下參數
f-
必要
預設值:無
要使用的欄位。
func-
必要
預設值:無
酬載函數。選項包括:
min、max、average或sum。 operator-
選用
預設值:無
搜尋運算子。 選項包括:*
or將產生SpanTermQuery或SpanOrQuery,具體取決於發出的符號數量。 *phrase將產生SpanTermQuery或有順序的、零坡度的SpanNearQuery,具體取決於發出的符號數量。 includeSpanScore-
選用
預設值:
false如果為
true,則將計算出的 payload 因子乘以原始查詢的分數。如果為false,則計算出的 payload 因子就是分數。
範例
{!payload_score f=my_field_dpf v=some_term func=max}{!payload_score f=payload_field func=sum operator=or}A B CPayload 檢查解析器
PayloadCheckQParser 僅在匹配的詞彙與 payload 也具有指定關係時才會匹配。預設關係是等於,但也可以執行不等於的匹配。這兩個解析器的主要查詢都直接從欄位類型的查詢分析解析為 SpanQuery。產生的 SpanQuery 將會是 SpanTermQuery 或依序的、零 slop 的 SpanNearQuery,具體取決於發出的 token 數量。最終的效果是,主要查詢的運作方式始終類似於標準 Lucene 解析器中的片語查詢(因此會忽略 q.op 的任何值)。
當對查詢套用欄位分析時,如果它改變了 token 的數量,則最終的 token 數量必須與 payloads 參數中提供的 payload 數量相符。如果查詢 token 的數量與此查詢提供的 payload 值數量不符,則查詢將不會匹配。 |
此解析器接受以下參數
f-
必要
預設值:無
要使用的欄位。
payloads-
必要
預設值:無
一個以空格分隔的 payload 列表,用於與文件中匹配的 token 中的 payload 進行比較。每個指定的 payload 都會在匹配之前使用從欄位類型確定的編碼器進行編碼。整數、浮點數和識別(字串)編碼都支援,其含義與
DelimitedPayloadTokenFilter相同。 op-
選用
預設值:
eq要應用於 payload 檢查的不等式運算。所有操作都要求從查詢分析中衍生的連續 token 與文件中連續的 token 相匹配,此外,文件 token 上的 payload 必須是:*
eq:等於指定的 payload *gt:大於指定的 payload *lt:小於指定的 payload *gte:大於或等於指定的 payload *lte:小於或等於指定的 payload
範例
尋找所有包含片語 "searching stuff" 的文件,其中 "searching" 的 payload 為 "VERB",而 "stuff" 的 payload 為 "NOUN"
{!payload_check f=words_dps payloads="VERB NOUN"}searching stuff尋找所有包含 "foo" 的文件,其中 "foo" 的 payload 的值大於或等於 0.75
{!payload_check f=words_dpf payloads="0.75" op="gte"}foo尋找所有包含片語 "foo bar" 的文件,其中詞彙 "foo" 的 payload 大於 9,而 "bar" 的 payload 大於 5
{!payload_check f=words_dpi payloads="9 5" op="gt"}foo bar
前綴查詢解析器
PrefixQParser 透過從輸入值建立前綴查詢來擴展 QParserPlugin。目前,沒有對此執行任何分析或值轉換來建立此前綴查詢。
參數是 f,即欄位。前綴宣告後的字串被視為萬用字元查詢。
範例
{!prefix f=myfield}foo這通常等同於 Lucene 查詢解析器表達式 myfield:foo*。
原始查詢解析器
RawQParser 透過從輸入值建立詞彙查詢來擴展 QParserPlugin,而不進行任何文字分析或轉換。這在除錯或從詞彙元件傳回原始詞彙時(這不是預設值)很有用。
唯一的參數是 f,它定義要搜尋的欄位。
範例
{!raw f=myfield}Foo Bar此範例建構查詢:TermQuery(Term("myfield","Foo Bar"))。
為了方便地建構篩選器以深入剖析 facet,建議使用 TermQParserPlugin。
對於所有欄位(包括文字欄位)的完整分析,您可能需要使用 FieldQParserPlugin。
排名查詢解析器
RankQParserPlugin 是 FunctionQParser 排名相關功能的更快實作,並且可以與 RankFields 類型的專用欄位一起使用。
它允許類似以下的查詢
https://127.0.0.1:8983/solr/techproducts?q=memory _query_:{!rank f='pagerank', function='log' scalingFactor='1.2'}重新排名查詢解析器
ReRankQParserPlugin 是一個專用解析器,用於使用更複雜的排名查詢重新排名簡單查詢的頂部結果。
有關使用 ReRankQParserPlugin 的詳細資訊,請參閱 查詢重新排名 一節。
簡單查詢解析器
Solr 中的簡單查詢解析器基於 Lucene 的 SimpleQueryParser。此查詢解析器旨在讓使用者以任何他們想要的方式輸入查詢,並且它會盡力解讀查詢並傳回結果。
此解析器接受以下參數
q.operators-
選用
預設值:請參閱說明
以逗號分隔的要啟用之解析運算子名稱的列表。預設情況下,會啟用所有運算子,並且可以使用此參數來根據需要有效地停用特定運算子,方法是將它們排除在列表之外。使用此參數傳遞空字串會停用所有運算子。
名稱 運算子 描述 查詢範例 AND+指定 AND
token1+token2OR|指定 OR
token1|token2NOT-指定 NOT
-token3PREFIX*指定前綴查詢
term*PHRASE"建立片語
"term1 term2"PRECEDENCE( )指定優先順序;括號內的 token 會先分析。否則,正常順序是從左到右。
token1 + (token2 | token3)ESCAPE\將其放在運算子前面以完全匹配它們
C+\+WHITESPACE空格或
[\r\t\n]以空格分隔 token。如果未啟用,則在分析之前不會執行空格分割 – 通常是最理想的。
不分割空格是此解析器的獨特功能,可讓多字詞同義詞正常運作。但是,除非將同義詞設定為正規化而不是擴展到符合給定同義詞的所有內容,否則它實際上可能不會這樣做。此類組態需要在索引時間和查詢時間正規化同義詞。Solr 的分析畫面可以在此處提供協助。
term1 term2FUZZY~~N在詞彙結尾,指定模糊查詢。
"N" 是可選的,可以是 "1" 或 "2"(預設值)
term~1NEAR~N在片語結尾,指定 NEAR 查詢
"term1 term2"~5 q.op-
選用
預設值:
OR定義如果使用者未定義時要使用的預設運算子。允許的值為
AND和OR。如果未指定任何值,則會使用OR。 qf-
選用
預設值:無
在建構查詢時要使用的查詢欄位和加權列表。
df-
選用
預設值:無
如果 Schema 中未定義,則定義預設欄位,或者覆寫已經定義的預設欄位。
語法中的任何錯誤都會被忽略,查詢解析器會盡力解讀查詢。但是,這在某些情況下可能會導致奇怪的結果。
空間查詢解析器
Solr 中有兩個空間 QParser:geofilt 和 bbox。但是,還有其他空間查詢方式:使用具有距離函數的 frange 解析器、使用具有範圍語法的標準 (lucene) 查詢解析器來選擇矩形的角,或者使用 RPT 和 BBoxField,您可以使用標準查詢解析器,但在引號內使用特殊語法來選擇空間謂詞。
所有這些選項都在 空間搜尋 一節中有進一步的說明。
環繞查詢解析器
SurroundQParser 啟用 Surround 查詢語法,該語法提供鄰近搜尋功能。有兩個位置運算子:w 建立已排序的 span 查詢,而 n 建立未排序的 span 查詢。這兩個運算子都採用數值來表示兩個詞彙之間的距離。預設值為 1,最大值為 99。
請注意,查詢字串不會以任何方式分析。
範例
{!surround} 3w(foo, bar)此範例會尋找詞彙 "foo" 和 "bar" 相距不超過 3 個詞彙的文件(即它們之間不超過 2 個詞彙)。
此查詢解析器也會接受布林運算子(AND、OR 和 NOT,無論大小寫)、萬用字元、用於片語搜尋的引號和加權。w 和 n 運算子也可以用大寫或小寫表示。
非一元運算子(除了 NOT 以外的所有運算子)都支援中綴 (a AND b AND c) 和前綴 AND(a, b, c) 標記法。
切換查詢解析器
SwitchQParser 是一個 QParserPlugin,其作用類似於「switch」或「case」陳述式。
主要輸入字串會被修剪,然後加上 case. 作為鍵值,用於在解析器的本機參數中查詢「switch case」。如果找到相符的本機參數,則產生的參數值將被解析為子查詢,並作為解析結果傳回。
case 本機參數可以選擇性地指定為要匹配遺失(或空白)輸入字串的 switch case。default 本機參數可以選擇性地指定為預設 case,以便在輸入字串與任何其他 switch case 本機參數不符時使用。如果未指定 default,則任何與 switch case 本機參數不符的輸入都會導致語法錯誤。
在下面的範例中,每個查詢的結果都是 "XXX"
{!switch case.foo=XXX case.bar=zzz case.yak=qqq}foo} 和 bar 之間的多餘空白會自動修剪。{!switch case.foo=qqq case.bar=XXX case.yak=zzz} bar{!switch case.foo=qqq case.bar=zzz default=XXX}asdfcase 的值。{!switch case=XXX case.bar=zzz case.yak=qqq}此解析器的一個實際用途是在 SearchHandler 的設定中指定 appends 篩選查詢 (fq) 參數,以便為使用自訂參數名稱的用戶端提供一組固定的篩選選項。
使用下面的範例設定,用戶端可以選擇性地指定自訂參數 in_stock 和 shipping 來覆寫預設篩選行為,但僅限於特定的合法值集 (shipping=any|free, in_stock=yes|no|all)。
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="in_stock">yes</str>
<str name="shipping">any</str>
</lst>
<lst name="appends">
<str name="fq">{!switch case.all='*:*'
case.yes='inStock:true'
case.no='inStock:false'
v=$in_stock}</str>
<str name="fq">{!switch case.any='*:*'
case.free='shipping_cost:0.0'
v=$shipping}</str>
</lst>
</requestHandler>詞彙查詢解析器
TermsQParser 的功能類似於 詞彙查詢解析器,但它會接收以逗號分隔的多個值,並傳回符合任何指定值的文件。
這對於從 facet 或詞彙元件傳回的外部人類可讀詞彙產生篩選查詢很有用,並且在某些情況下可能比使用 標準查詢解析器 產生布林查詢更有效率,因為預設實作 method 會避免評分。
此查詢解析器接受以下參數
f-
必要
預設值:無
要搜尋的欄位。
separator-
選用
預設值:
,(逗號)解析輸入時使用的分隔符號。如果設定為 " " (單一空白),將會移除輸入詞語中多餘的空白。
方法 (method)-
選用
預設值:
termsFilter決定 Solr 應使用哪一種查詢實作方式。
選項限制為:
termsFilter、booleanQuery、automaton、docValuesTermsFilterPerSegment、docValuesTermsFilterTopLevel或docValuesTermsFilter。每種實作方式都有其效能特性,建議使用者進行實驗,以決定哪種實作方式最符合其使用案例的效能需求。以下提供一些經驗法則。
booleanQuery會建立一個代表請求的BooleanQuery。在索引大小方面擴展性良好,但在搜尋的詞語數量方面擴展性較差。termsFilter會根據詞語數量使用BooleanQuery或TermInSetQuery。在索引大小方面擴展性良好,但在查詢詞語數量方面僅適度擴展。docValuesTermsFilter只能用於具有 docValues 資料的欄位。cache參數預設為 false。它會根據查詢詞語的數量,在docValuesTermsFilterTopLevel和docValuesTermsFilterPerSegment方法之間選擇。使用者通常應使用此方法,而不是直接使用docValuesTermsFilterTopLevel或docValuesTermsFilterPerSegment,除非他們已進行效能測試,以驗證其中一種方法適用於所有大小的查詢。根據選擇的實作方式,此方法可能會依賴於在每次提交後延遲建立的昂貴資料結構。如果您的提交頻繁,且您的使用案例可以容忍靜態預熱查詢,請考慮將一個預熱查詢添加到solrconfig.xml中,以便此工作可以在提交時完成,而不是直接附加到使用者請求中。docValuesTermsFilterTopLevel只能用於具有 docValues 資料的欄位。cache參數預設為 false。它使用頂層 docValues 資料結構來尋找結果。當查詢詞語數量增加到很高時(超過數百個),這些資料結構會更有效率。但它們的建置成本也很高,並且需要在每次提交後延遲建立,這會在每次提交後的第一個查詢時導致明顯的效能下降。如果您的提交頻繁,且您的使用案例可以容忍靜態預熱查詢,請考慮將一個預熱查詢添加到solrconfig.xml中,以便此工作可以在提交時完成,而不是直接附加到使用者請求中。docValuesTermsFilterPerSegment只能用於具有 docValues 資料的欄位。cache參數預設為 false。在查詢詞語數量較少到中等 (~500) 時,它比「頂層」替代方案更有效率,並且在提交後立即進行查詢時不會出現效能下降(如docValuesTermsFilterTopLevel那樣 - 請參閱上文)。但在查詢詞語數量非常大時,其效能較差。automaton會建立一個AutomatonQuery來表示請求,其中每個詞語形成一個聯集。在索引大小方面擴展性良好,在查詢詞語數量方面則適度擴展。
範例
{!terms f=tags}software,apache,solr,lucene{!terms f=categoryId method=booleanQuery separator=" "}8 6 7 5309XML 查詢解析器
XmlQParserPlugin 擴展了 QParserPlugin,並支援從 XML 建立查詢。範例
| 參數 (Parameter) | 值 (Value) |
|---|---|
defType |
|
q |
|
XmlQParser 實作使用 SolrCoreParser 類別,該類別擴展了 Lucene 的 CoreParser 類別。XML 元素會對應到 QueryBuilder 類別,如下所示
| XML 元素 | QueryBuilder 類別 |
|---|---|
<BooleanQuery> |
|
<BoostingTermQuery> |
|
<ConstantScoreQuery> |
|
<DisjunctionMaxQuery> |
|
<MatchAllDocsQuery> |
|
<RangeQuery> |
|
<SpanFirst> |
|
<SpanPositionRange> |
|
<SpanNear> |
|
<SpanNot> |
|
<SpanOr> |
|
<SpanOrTerms> |
|
<SpanTerm> |
|
<TermQuery> |
|
<TermsQuery> |
|
<UserQuery> |
|
<LegacyNumericRangeQuery> |
LegacyNumericRangeQuery(Builder) 已棄用 |
自訂 XML 查詢解析器
您可以為額外的 XML 元素設定您自己的自訂查詢建構器。自訂建構器需要擴展 SolrQueryBuilder 或 SolrSpanQueryBuilder 類別。範例 solrconfig.xml 片段
<queryParser name="xmlparser" class="XmlQParserPlugin">
<str name="MyCustomQuery">com.mycompany.solr.search.MyCustomQueryBuilder</str>
</queryParser>