分析畫面
一旦您在您的結構描述中定義欄位類型,並指定您想要套用的分析步驟後,您應該測試一下,以確保它的行為符合您的預期。
幸運的是,Solr 管理介面中有一個非常方便的頁面可以讓您做到這一點。您可以針對任何文字欄位叫用分析器、提供範例輸入,並顯示產生的符記串流。
例如,讓我們看看 bin/solr start -e techproducts 範例組態中可用的一些「文字」欄位類型,並使用分析畫面 (https://127.0.0.1:8983/solr/#/techproducts/analysis) 來比較句子「Running an Analyzer」在索引時產生的符記,與略有不同的查詢文字「run my analyzer」如何匹配。
我們可以從 text_ws 開始,它是最簡化的文字欄位類型之一
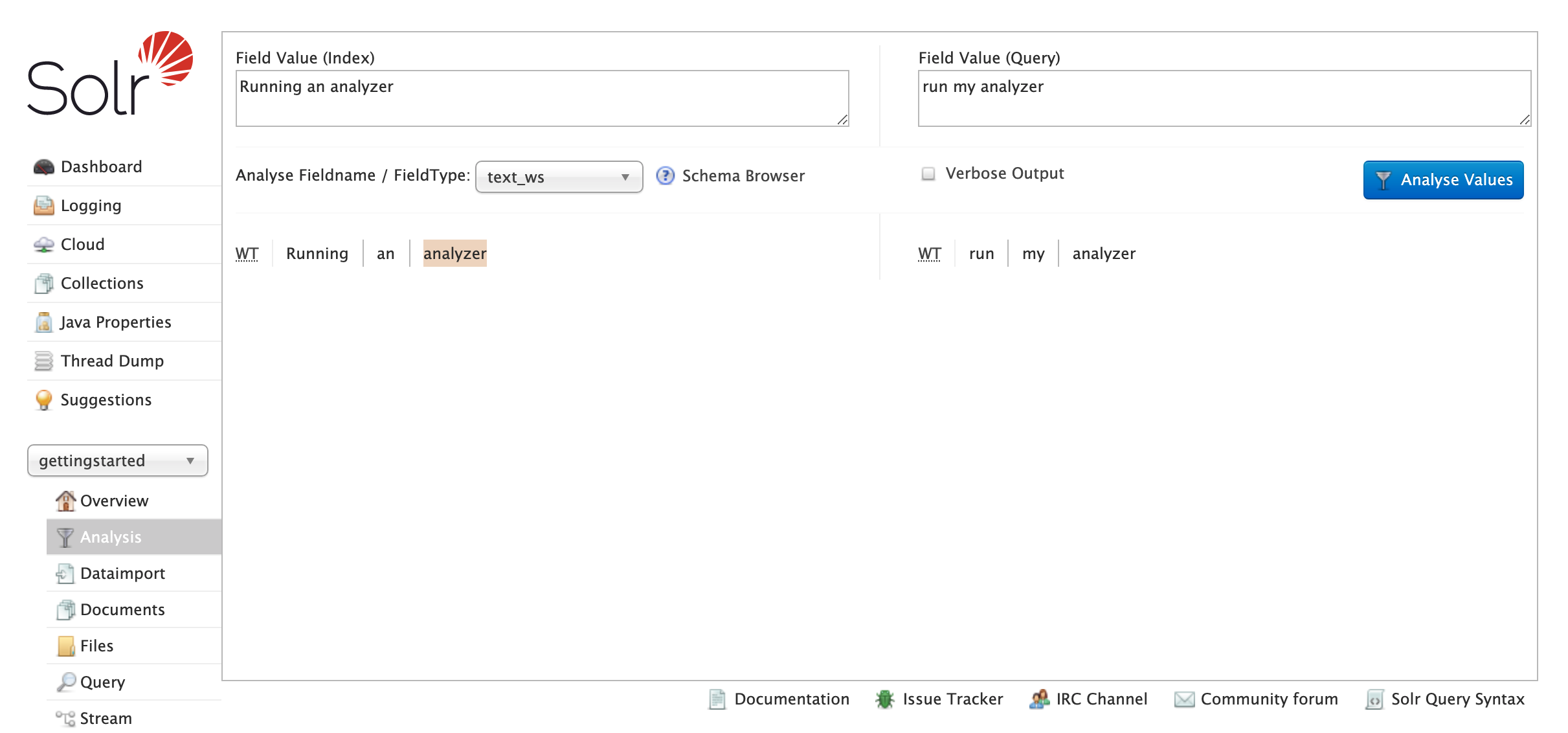
這會顯示分析的每個步驟 (在此案例中為單一步驟) 產生的符記的簡單輸出。斷詞器會以縮寫顯示,將滑鼠游標移至此處或按一下此處可查看完整名稱。
如果我們勾選方塊來啟用「詳細輸出」,則會顯示更多詳細資訊
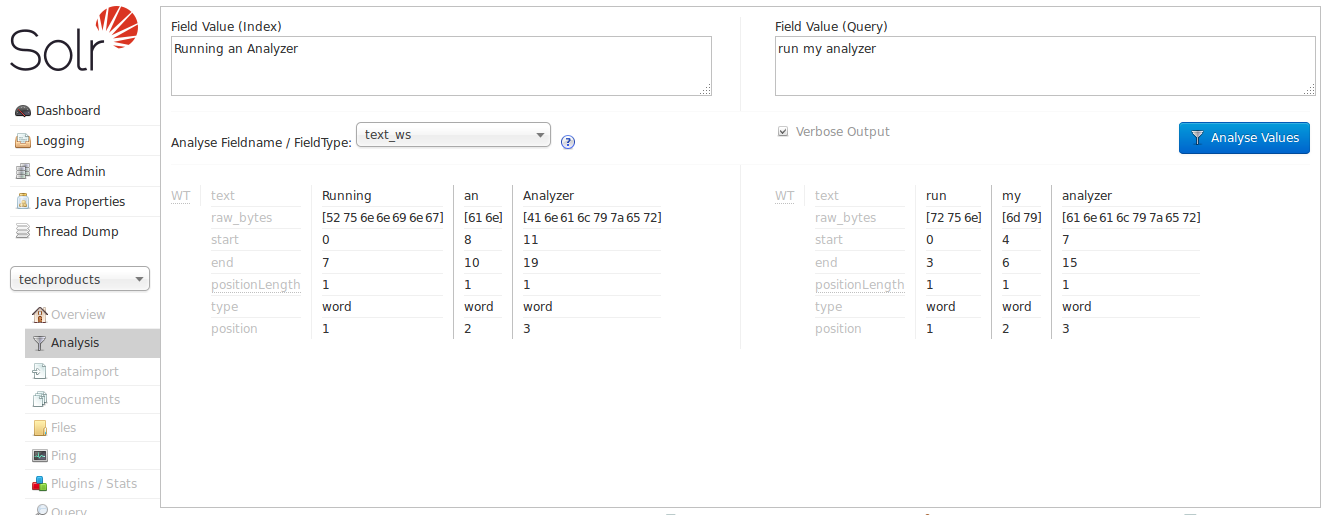
透過查看每個詞彙的開始與結束位置,我們可以看到此欄位類型所做的唯一事情是將文字以空白字元斷詞。請注意,在此影像中,詞彙「Running」的開始位置為 0,結束位置為 7,而「an」的開始位置為 8,結束位置為 10,「Analyzer」的開始位置為 11,結束位置為 19。如果也包含詞彙之間的空白字元,則計數會是 21;由於它是 19,因此我們知道空白字元已從此查詢中移除。
另請注意,索引詞彙與查詢詞彙仍然非常不同。「Running」與「run」不匹配,「Analyzer」與「analyzer」不匹配 (對電腦而言),而「an」與「my」顯然是完全不同的字詞。如果我們的目標是允許「run my analyzer」之類的查詢與「Running an Analyzer」之類的索引文字相符,則我們需要選擇不同的欄位類型,其索引和查詢時間文字分析可對輸入進行更多處理。
特別是,我們想要
-
大小寫不敏感,因此「Analyzer」和「analyzer」可以匹配。
-
詞幹處理,因此「Run」和「Running」之類的字詞會被視為等效詞彙。
-
停用字詞修剪,因此「an」和「my」之類的小字詞不會影響查詢。
接下來,我們嘗試使用 text_general 欄位類型。
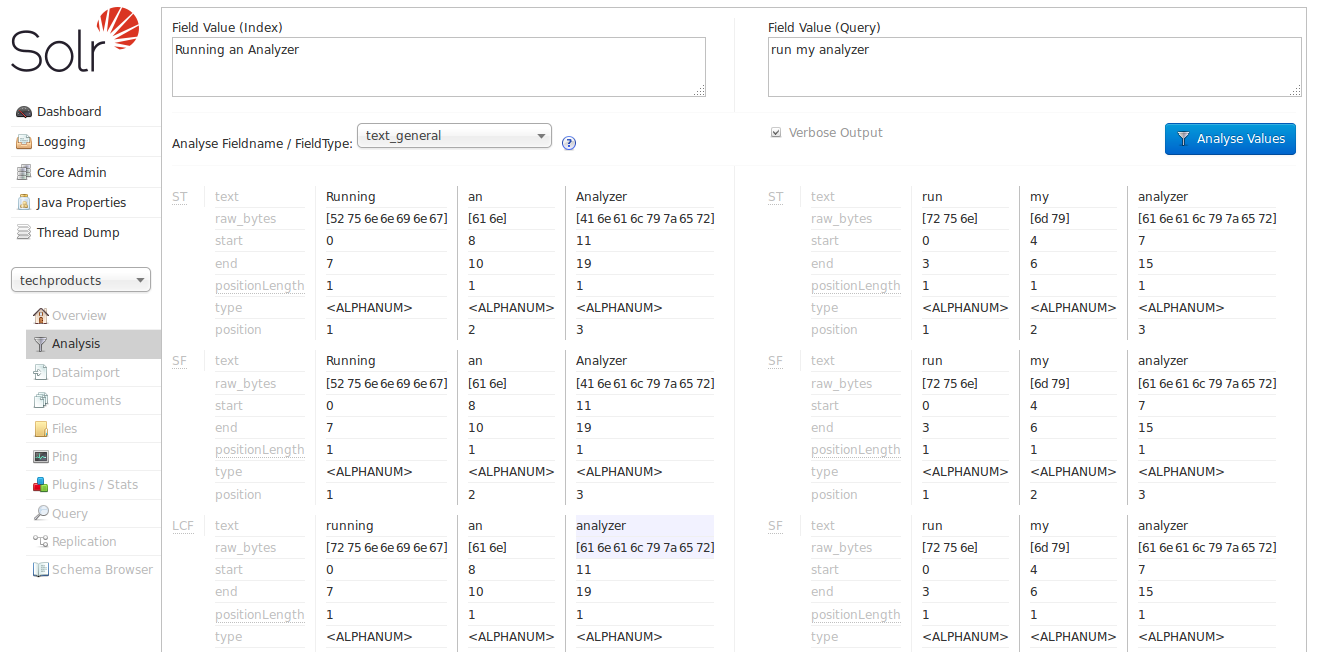
啟用詳細輸出後,我們可以檢視新分析器每個階段如何修改接收到的詞彙單元,然後將其傳遞到下一個階段。當我們向下捲動到最終輸出時,可以看到由於 "LCF" 階段,我們確實開始從每個輸入字串中得到 "analyzer" 的匹配項。將滑鼠游標懸停在 "LCF" 上,你會看到它是 LowerCaseFilter(小寫過濾器)。
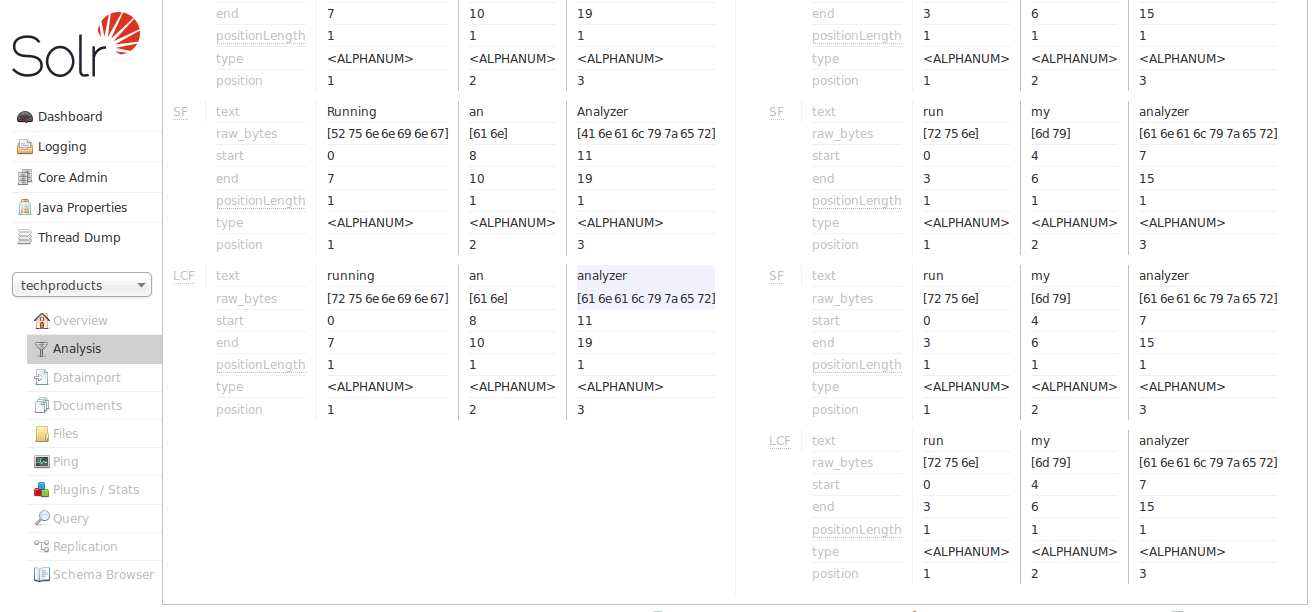
text_general 欄位類型旨在普遍適用於任何語言,並且它確實比我們第一個範例中的 text_ws 更接近我們的目標,它解決了大小寫敏感性的問題。但這仍然不是我們想要的結果,因為我們沒有看到應用詞幹還原或停用詞規則。因此,現在讓我們嘗試 text_en 欄位類型。
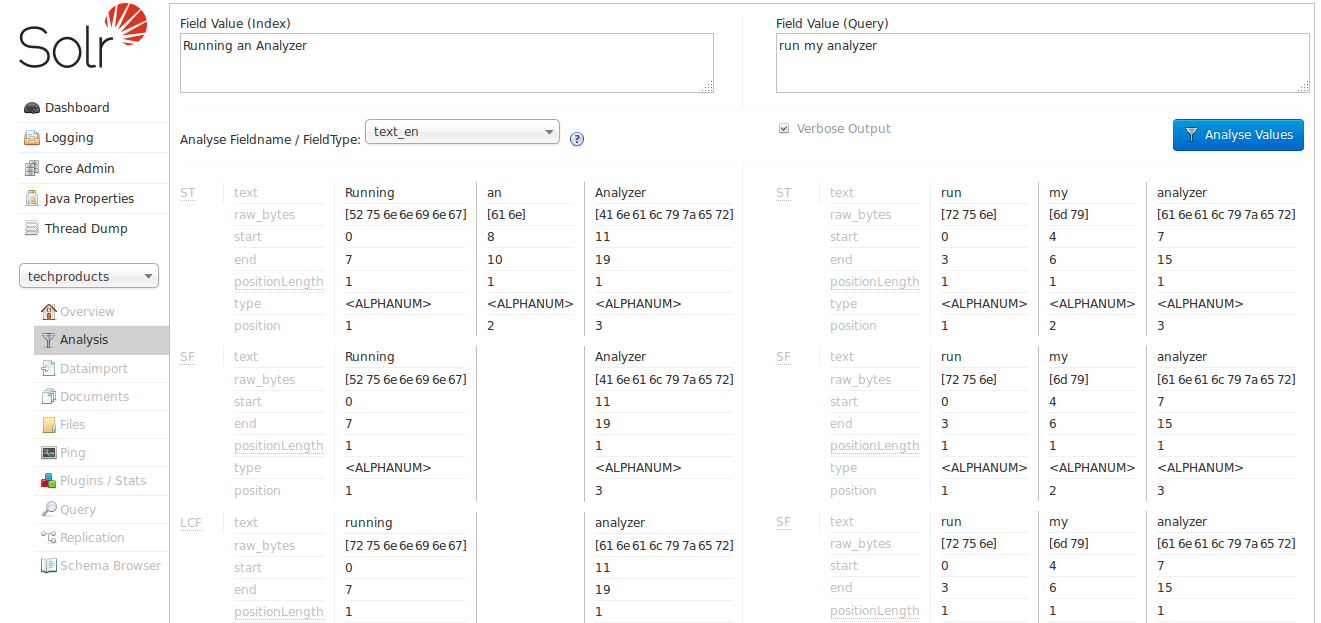
現在我們可以看到分析器的 "SF" (StopFilter,停用詞過濾器) 階段解決了移除停用詞("an")的問題。當我們向下捲動時,我們還看到 "PSF" (PorterStemFilter,波特詞幹過濾器) 階段應用了適用於我們英語輸入的詞幹還原規則,使得我們的「索引分析器」產生的詞彙單元與我們的「查詢分析器」產生的詞彙單元按照我們預期的方式匹配。
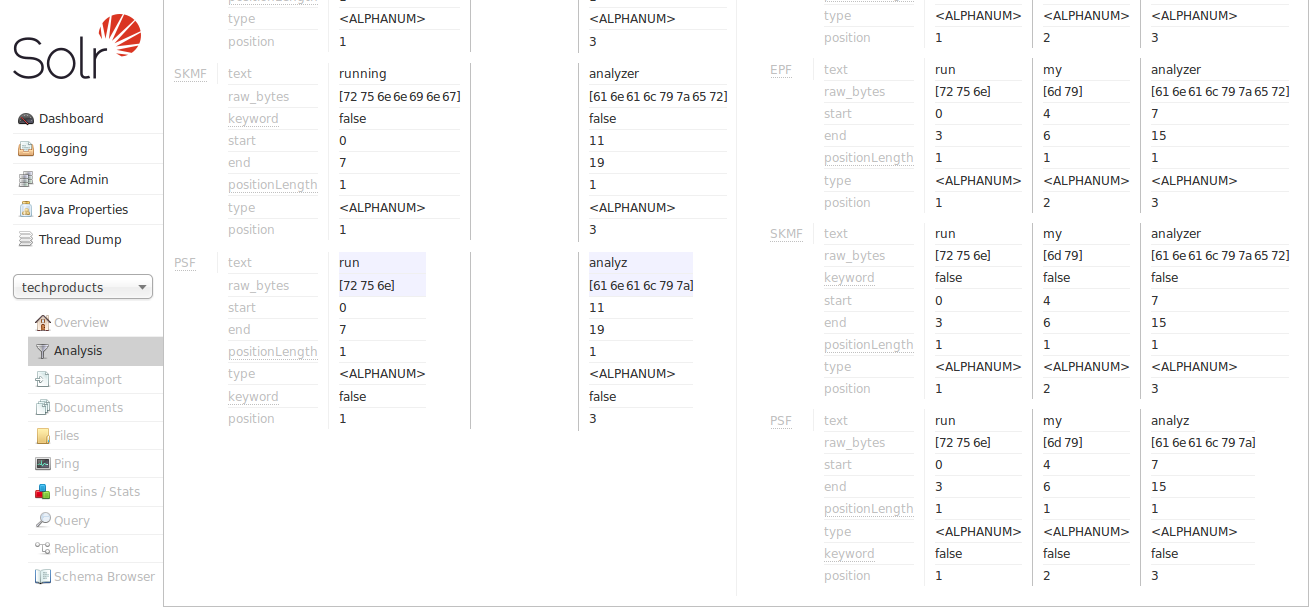
此時,我們可以繼續嘗試額外的輸入,驗證我們的分析器在我們預期匹配時產生匹配的詞彙單元,在我們不預期匹配時產生不同的詞彙單元,隨著我們迭代和調整欄位類型配置。