載入資料
串流運算式支援讀取、剖析、轉換、視覺化和載入 CSV 和 TSV 格式的資料。這些函式的設計目的是減少資料準備所花費的時間,並讓使用者在資料載入 Solr 之前開始探索資料。
讀取檔案
cat 函式可用於讀取 $SOLR_HOME 中 userfiles 目錄下的檔案。此目錄必須由使用者建立。cat 函式採用兩個參數。
第一個參數是以逗號分隔的路徑清單。如果路徑清單包含目錄,cat 會掃描目錄及其子目錄中的所有檔案。如果路徑清單僅包含檔案,則 cat 只會讀取特定檔案。
第二個參數 maxLines 會告知 cat 總共要讀取多少行。如果未提供 maxLines,則 cat 會讀取它掃描的每個檔案中的所有行。
cat 函式會讀取掃描檔案中的每一行(最多 maxLines),並且針對每一行,會發出一個具有兩個欄位的元組
-
line:該行中的文字。 -
file:$SOLR_HOME下檔案的相對路徑。
以下是 cat 在 iris.csv 檔案上的範例,maxLines 為 5
cat("iris.csv", maxLines="5")當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"line": "sepal_length,sepal_width,petal_length,petal_width,species",
"file": "iris.csv"
},
{
"line": "5.1,3.5,1.4,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.9,3,1.4,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.7,3.2,1.3,0.2,setosa",
"file": "iris.csv"
},
{
"line": "4.6,3.1,1.5,0.2,setosa",
"file": "iris.csv"
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}剖析 CSV 和 TSV 檔案
parseCSV 和 parseTSV 函式會包裝 cat 函式,並剖析 CSV(逗號分隔值)和 TSV(Tab 分隔值)。這兩個函式都預期每個檔案開頭都有 CSV 或 TSV 標頭記錄。
parseCSV 和 parseTSV 都會發出將標頭值對應到每一行中對應值的元組。
parseCSV(cat("iris.csv", maxLines="5"))當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"sepal_width": "3.5",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "5.1",
"id": "iris.csv_2",
"petal_length": "1.4"
},
{
"sepal_width": "3",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.9",
"id": "iris.csv_3",
"petal_length": "1.4"
},
{
"sepal_width": "3.2",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.7",
"id": "iris.csv_4",
"petal_length": "1.3"
},
{
"sepal_width": "3.1",
"species": "setosa",
"petal_width": "0.2",
"sepal_length": "4.6",
"id": "iris.csv_5",
"petal_length": "1.5"
},
{
"EOF": true,
"RESPONSE_TIME": 1
}
]
}
}視覺化
一旦將資料剖析成具有 parseCSV 或 parseTSV 的元組後,就可以使用 Zeppelin-Solr 將其視覺化。
以下範例顯示 parseCSV 函式的輸出,其視覺化為表格。
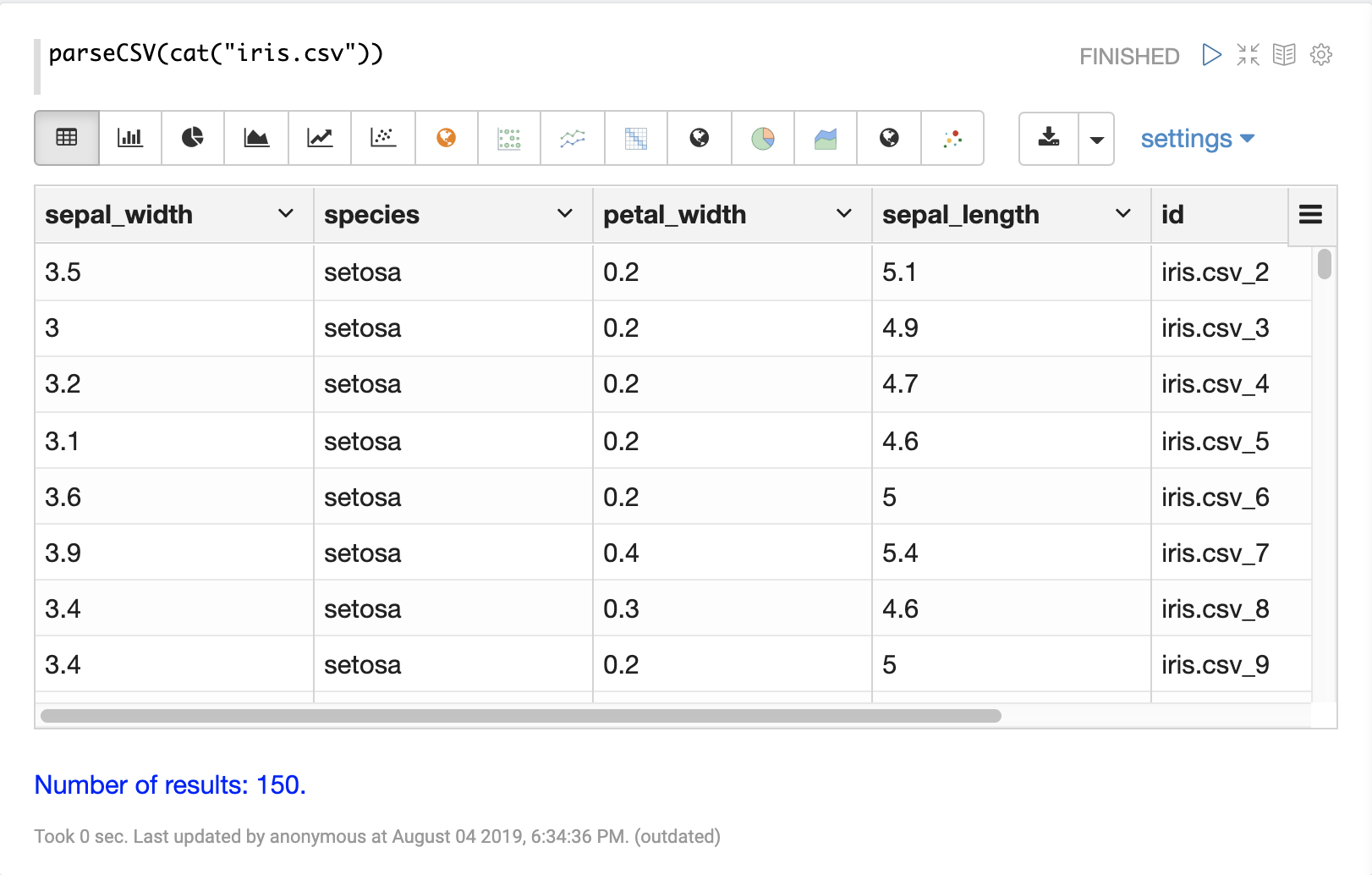
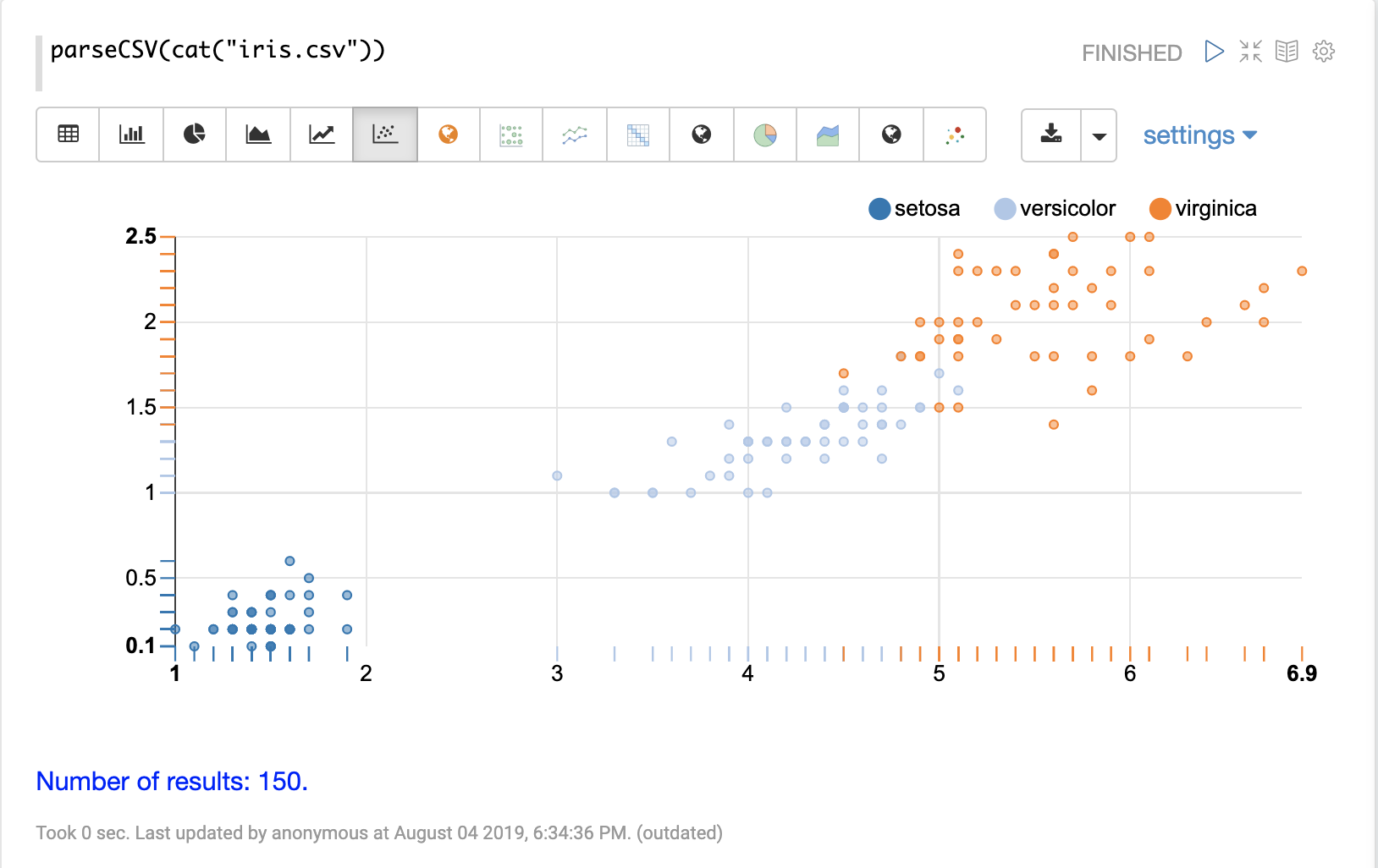
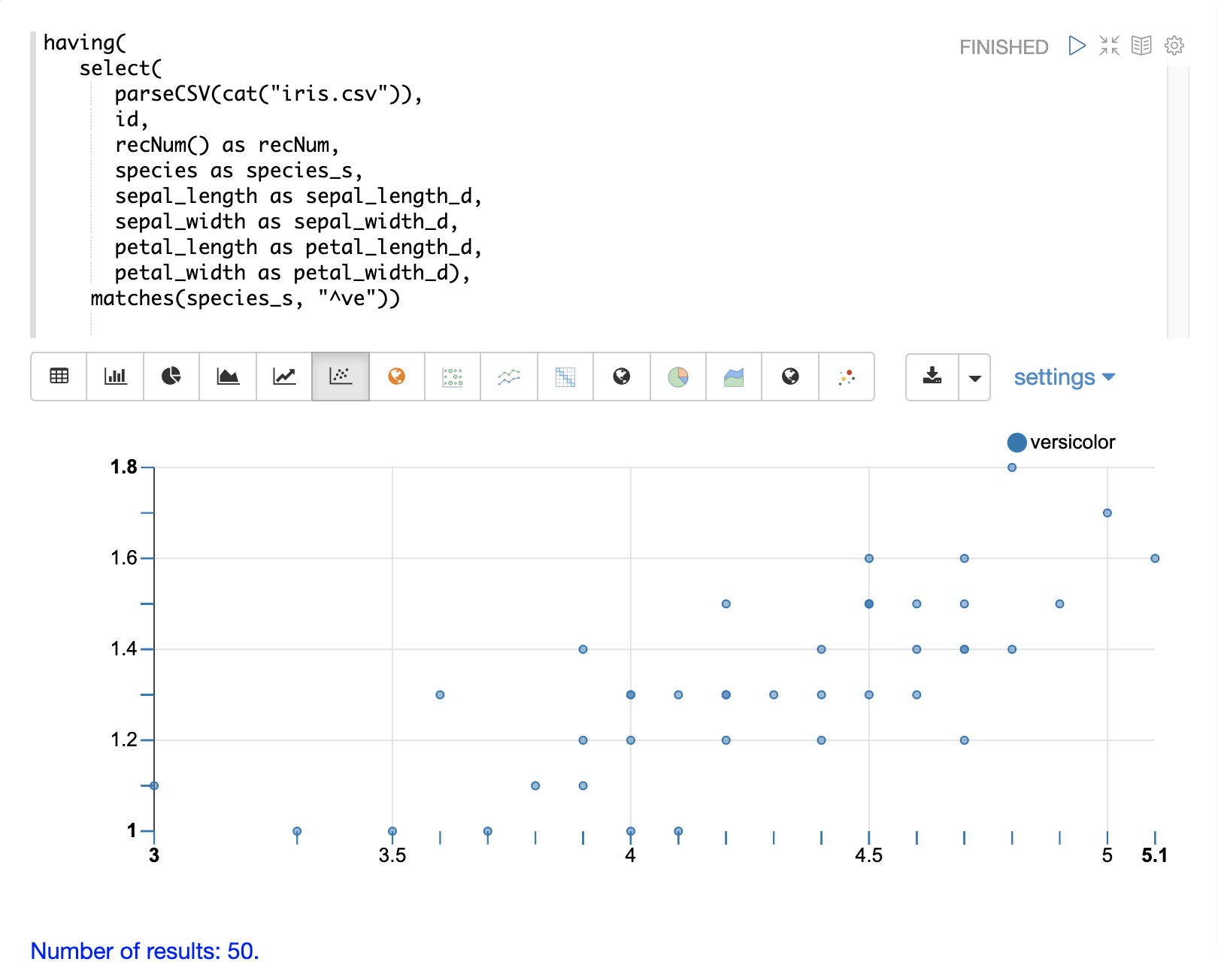
然後可以使用 Apache Zeppelin 的視覺化效果之一來視覺化表格中的欄。以下範例顯示以 species 分組的 petal_length 和 petal_width 散佈圖。
選取欄位與欄位類型
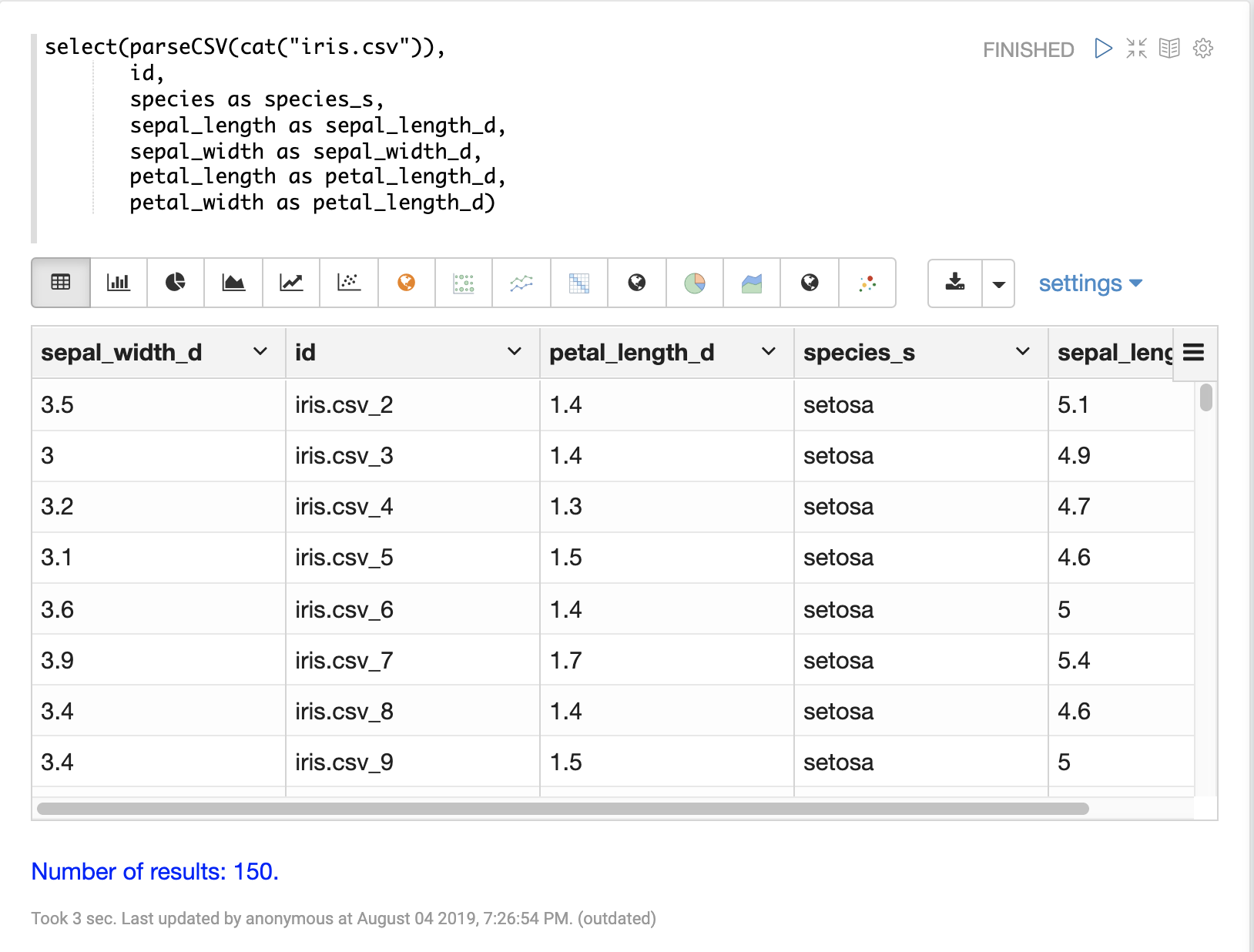
select 函式可用於從 CSV 檔案中選取特定欄位,並將其對應到要建立索引的新欄位名稱。
CSV 檔案中的欄位可以使用動態欄位後綴對應到欄位名稱。這種方法可以在不必變更綱要檔案的情況下,精細控制綱要欄位類型。
以下是選取欄位並將其對應到特定欄位類型的範例。
載入資料
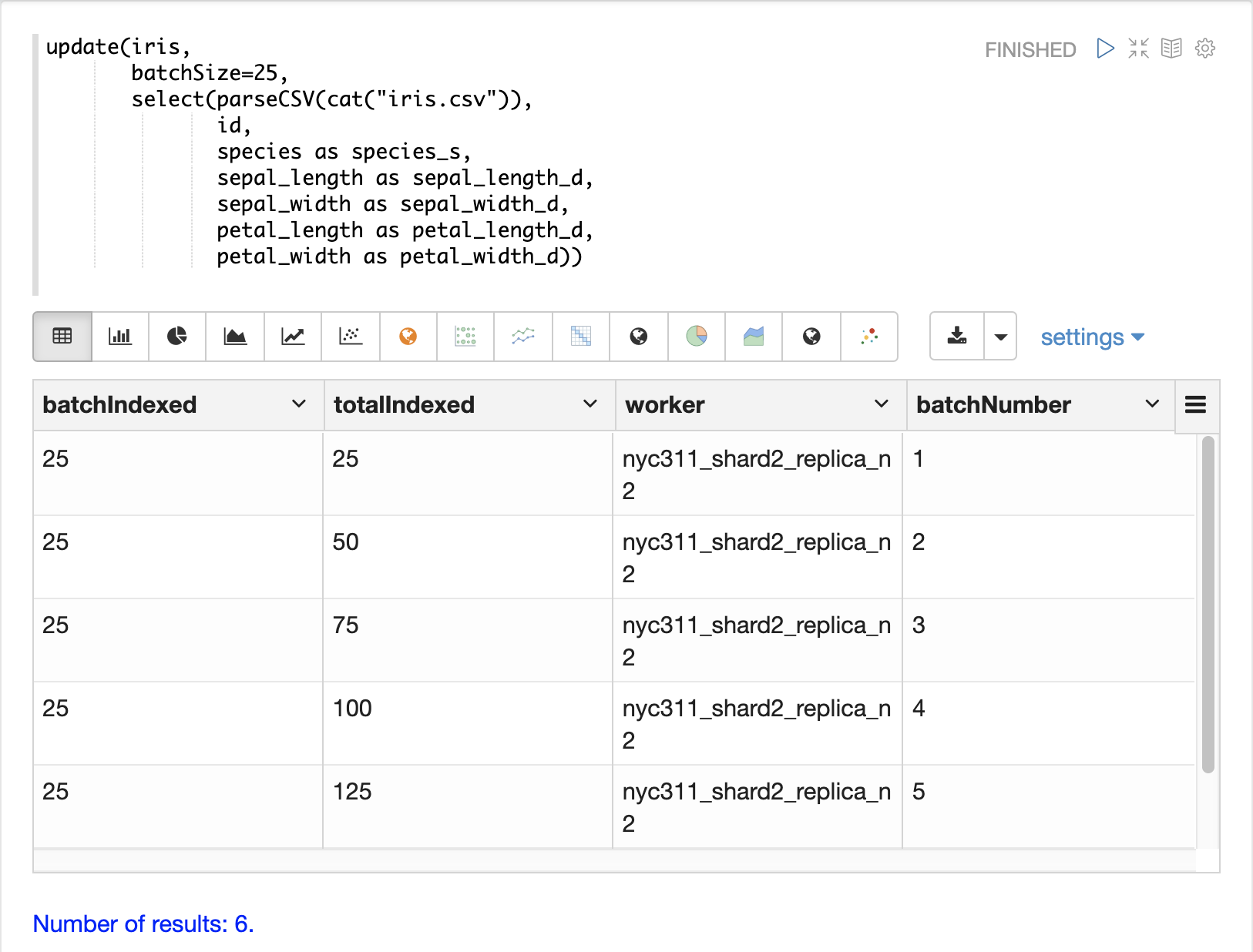
當資料準備好載入時,可以使用 update 函式將資料傳送到 SolrCloud 集合以建立索引。update 函式會以批次方式將文件新增至 Solr,並針對每個批次傳回一個元組,其中包含關於批次與載入的摘要資訊。
在以下範例中,update 運算式是使用 Zeppelin-Solr 執行的,因為資料集很小。對於較大的載入,最好是從 curl 命令執行載入,其中 update 函式的輸出可以假脫機處理到磁碟。
轉換資料
串流運算式和數學運算式提供了一組強大的函式,可用於轉換資料。以下章節說明了一些在分析、視覺化和載入 CSV 及 TSV 檔案時可以套用的實用轉換。
唯一 ID
如果資料中沒有 id 欄位,parseCSV 和 parseTSV 都會發出一個 id 欄位。id 欄位是檔案路徑和行號的串聯。如果檔案中沒有 id,這是一種確保記錄具有一致 id 的方便方法。
您也可以使用 select 函式將檔案中的任何欄位對應到 id 欄位。concat 函式可用於串聯檔案中的兩個或多個欄位以建立 id。或者,可以使用 uuid 函式建立隨機唯一 id。如果使用 uuid 函式,則必須先刪除資料才能重新載入資料,因為 uuid 函式在後續載入時不會為每個文件產生相同的 id。
以下是一個使用 concat 函式建立新 id 的範例。
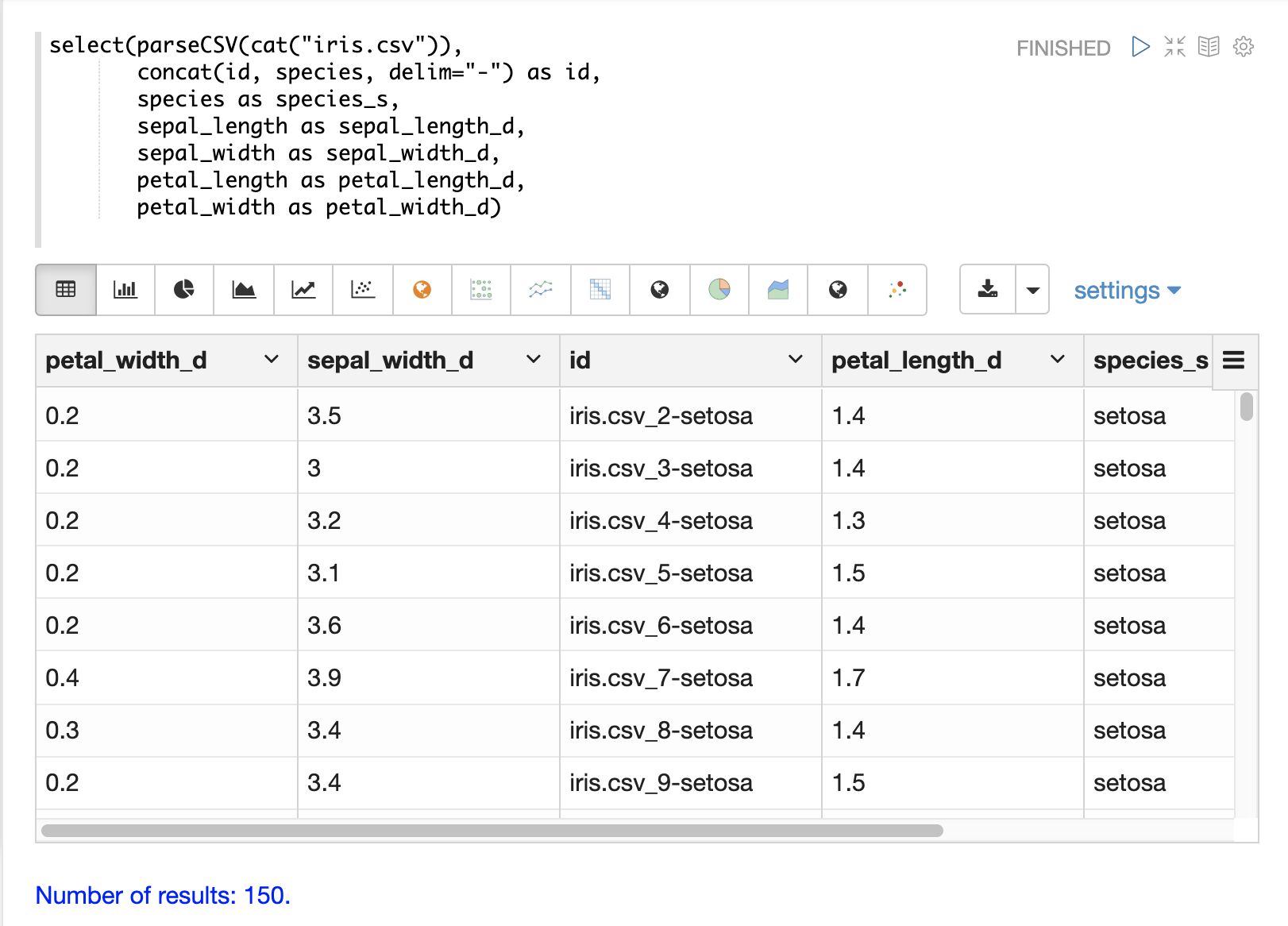
以下是一個使用 uuid 函式建立新 id 的範例。
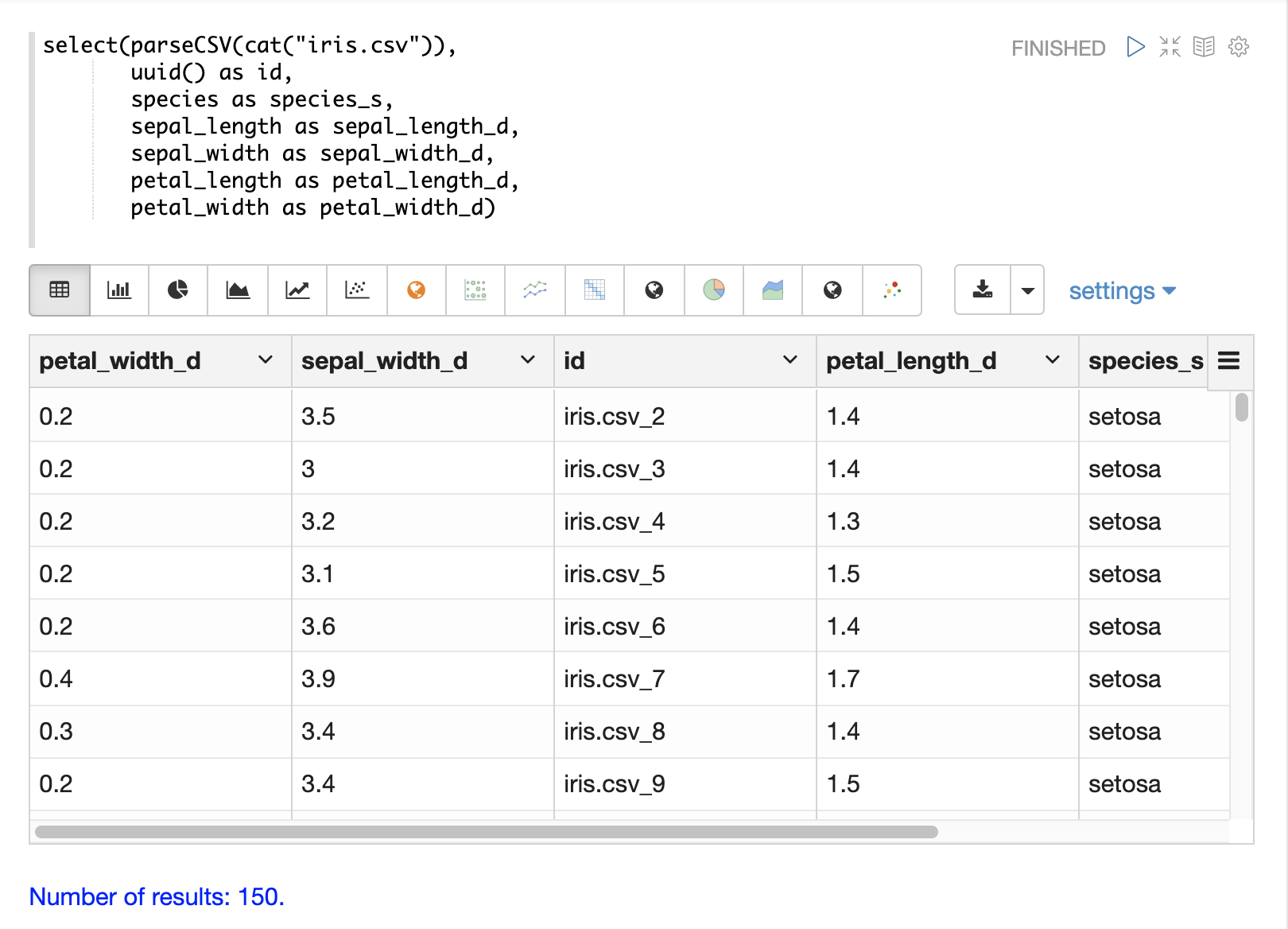
記錄編號
recNum 函式可以在 select 函式內使用,為每個元組新增一個記錄編號。記錄編號對於追蹤結果集中的位置非常有用,並且可以用於篩選策略,例如在下方的「篩選結果」章節中所述的跳過、分頁和步進。
以下範例顯示了 recNum 函式的語法

剖析日期
dateTime 函式可用於將日期剖析為載入 Solr 日期欄位所需的 ISO-8601 格式。
我們可以先檢查 CSV 檔案中日期時間欄位的格式
select(parseCSV(cat("yr2017.csv", maxLines="2")),
id,
Created.Date)當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"id": "yr2017.csv_2",
"Created.Date": "01/01/2017 12:00:00 AM"
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}然後我們可以使用 dateTime 函式來格式化日期時間並將其對應到 Solr 日期欄位。
dateTime 函式接受三個參數。資料中包含日期字串的欄位、使用 Java SimpleDateFormat 樣板剖析日期的樣板,以及可選的時區。
如果沒有時區,則時區預設為 GMT 時間,除非日期字串本身包含時區。
以下是在上述範例中套用於日期格式的 dateTime 函式範例。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
id,
dateTime(Created.Date, "MM/dd/yyyy hh:mm:ss a", "EST") as cdate_dt)當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"cdate_dt": "2017-01-01T05:00:00Z",
"id": "yr2017.csv_2"
},
{
"EOF": true,
"RESPONSE_TIME": 1
}
]
}
}字串操作
upper、lower、split、valueAt、trim 和 concat 函式可用於操作 select 函式內的字串。
以下範例顯示了 upper 函式用於將 species 欄位轉換為大寫。
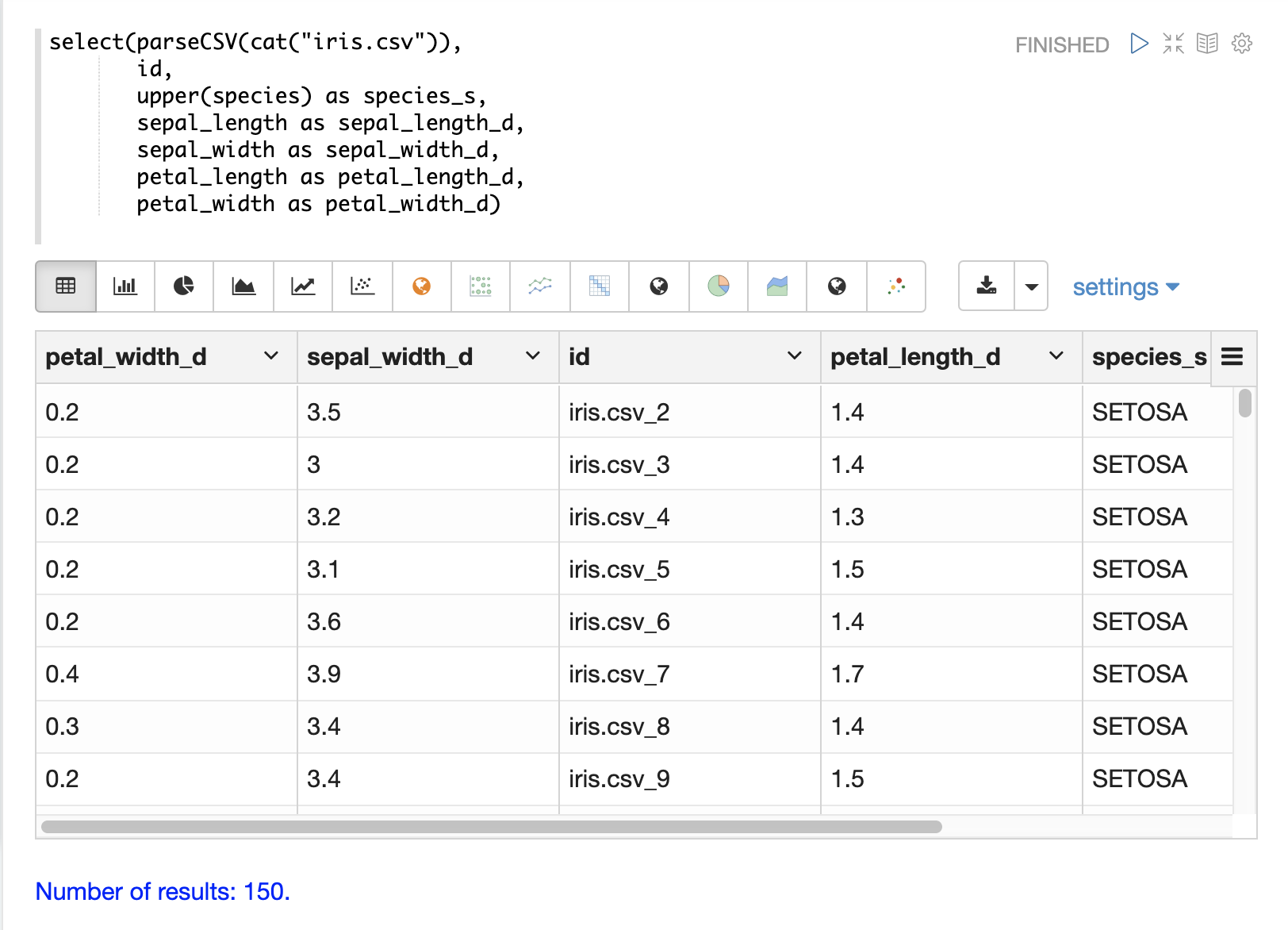
以下範例顯示了 split 函式,該函式會依據分隔符號分割欄位。這可用於從具有內部分隔符號的欄位建立多值欄位。
以下範例透過直接呼叫 /stream 處理常式來示範此操作
select(parseCSV(cat("iris.csv")),
id,
split(id, "_") as parts_ss,
species as species_s,
sepal_length as sepal_length_d,
sepal_width as sepal_width_d,
petal_length as petal_length_d,
petal_width as petal_width_d)當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"petal_width_d": "0.2",
"sepal_width_d": "3.5",
"id": "iris.csv_2",
"petal_length_d": "1.4",
"species_s": "setosa",
"sepal_length_d": "5.1",
"parts_ss": [
"iris.csv",
"2"
]
},
{
"petal_width_d": "0.2",
"sepal_width_d": "3",
"id": "iris.csv_3",
"petal_length_d": "1.4",
"species_s": "setosa",
"sepal_length_d": "4.9",
"parts_ss": [
"iris.csv",
"3"
]
}]}}valueAt 函式可用於從分割陣列中選取特定索引。
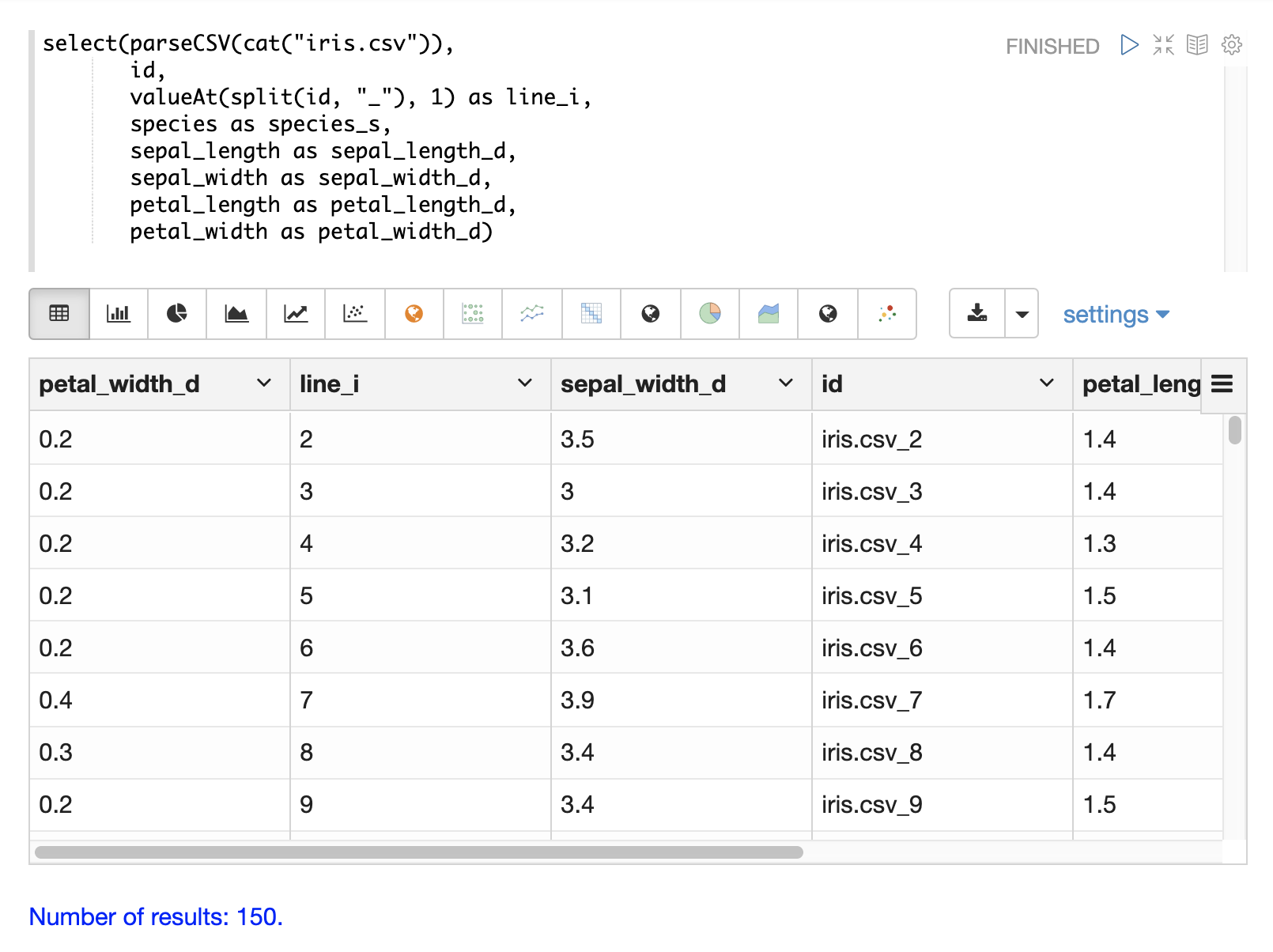
篩選結果
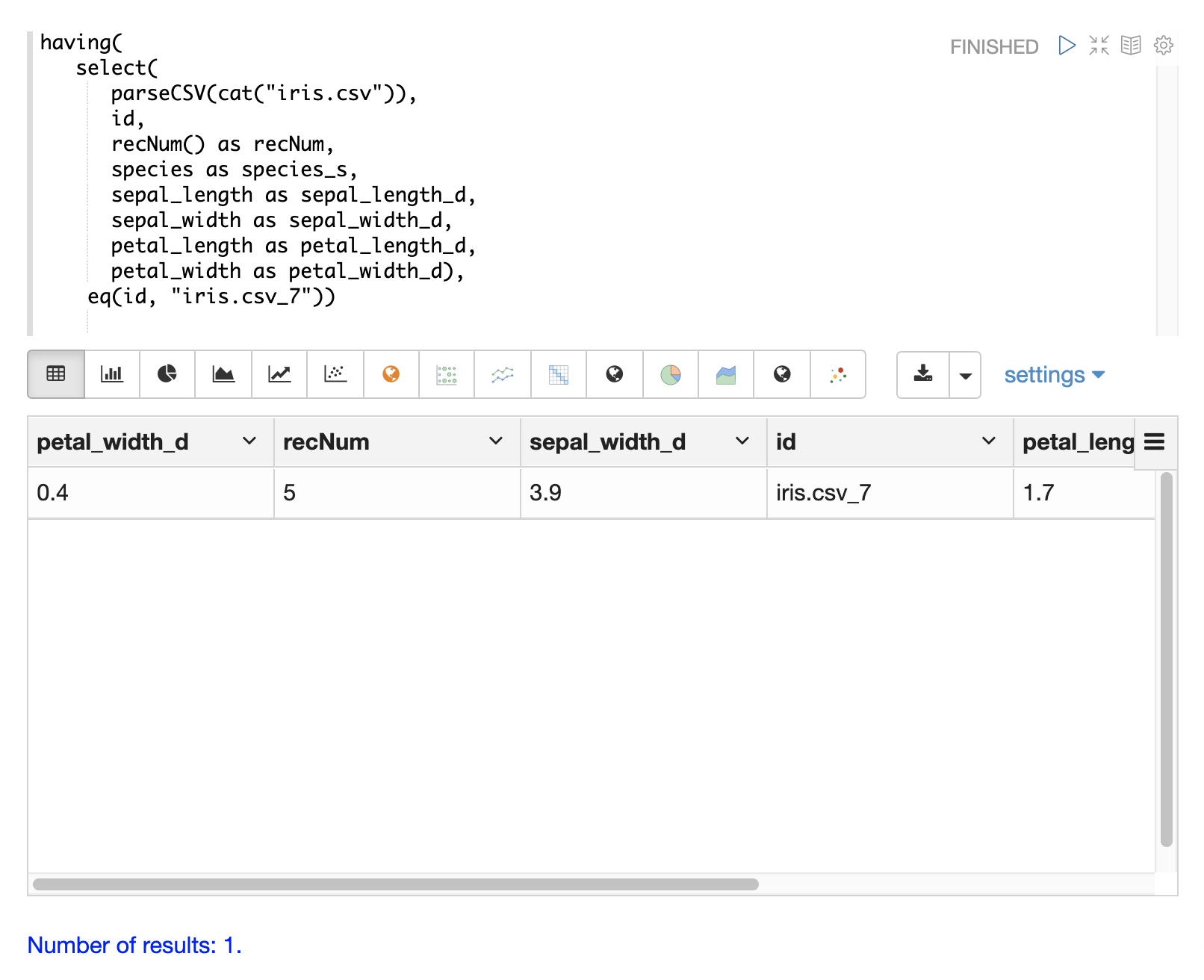
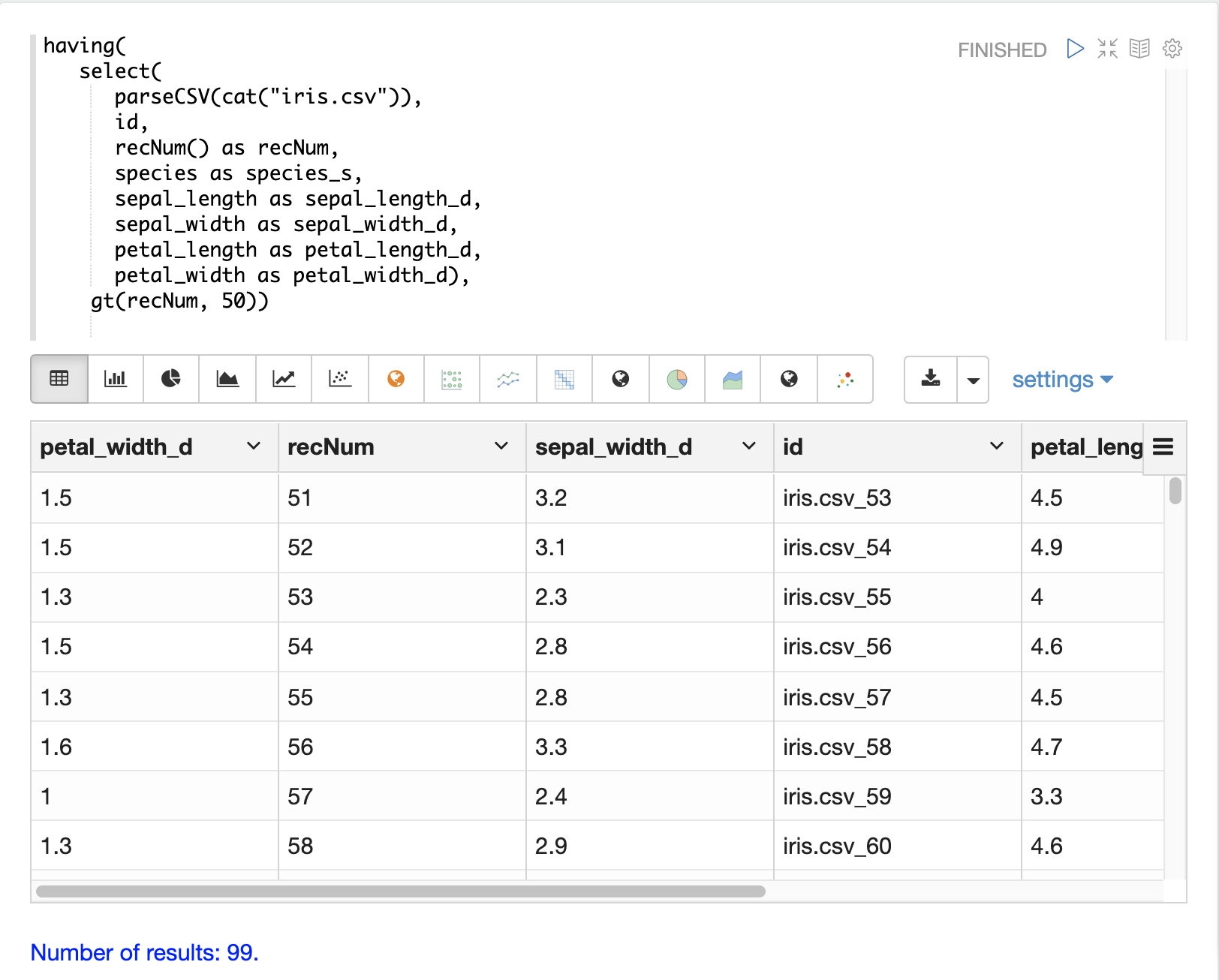
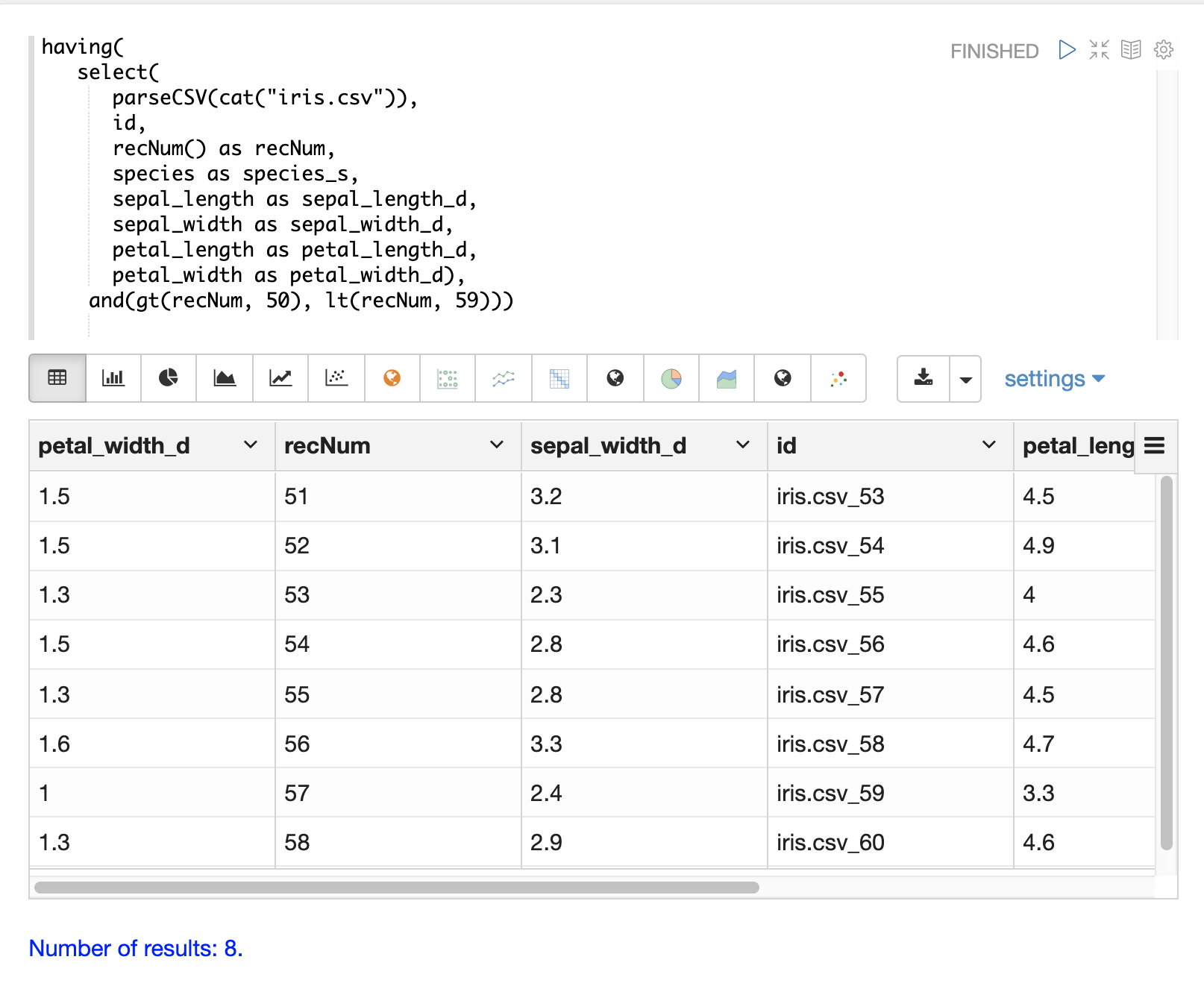
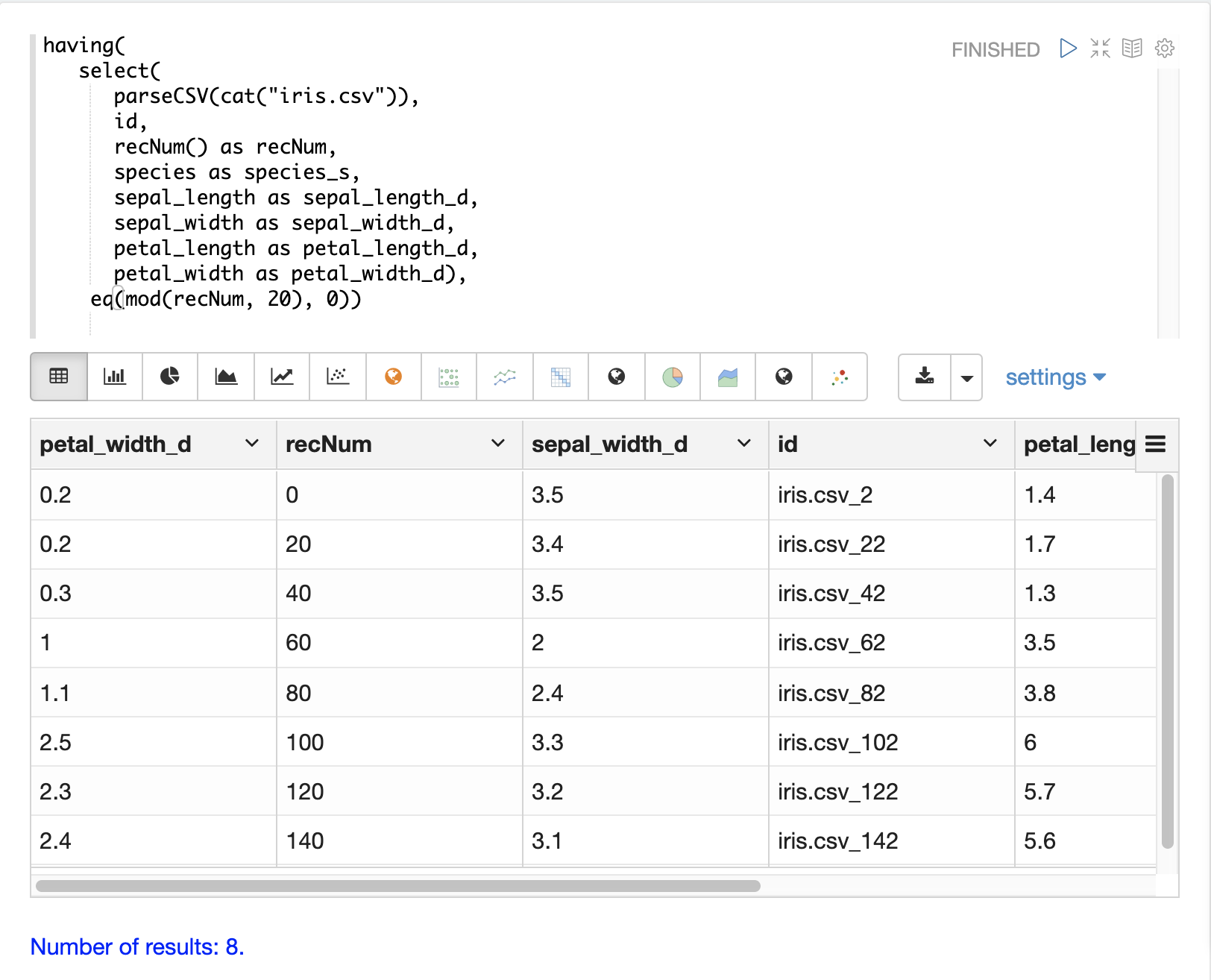
having 函式可用於篩選記錄。篩選可用於在建立索引之前系統地探索特定記錄集,或篩選要傳送以建立索引的記錄。having 函式會包裝另一個串流,並將布林函式套用於每個元組。如果布林邏輯函式傳回 true,則會傳回該元組。
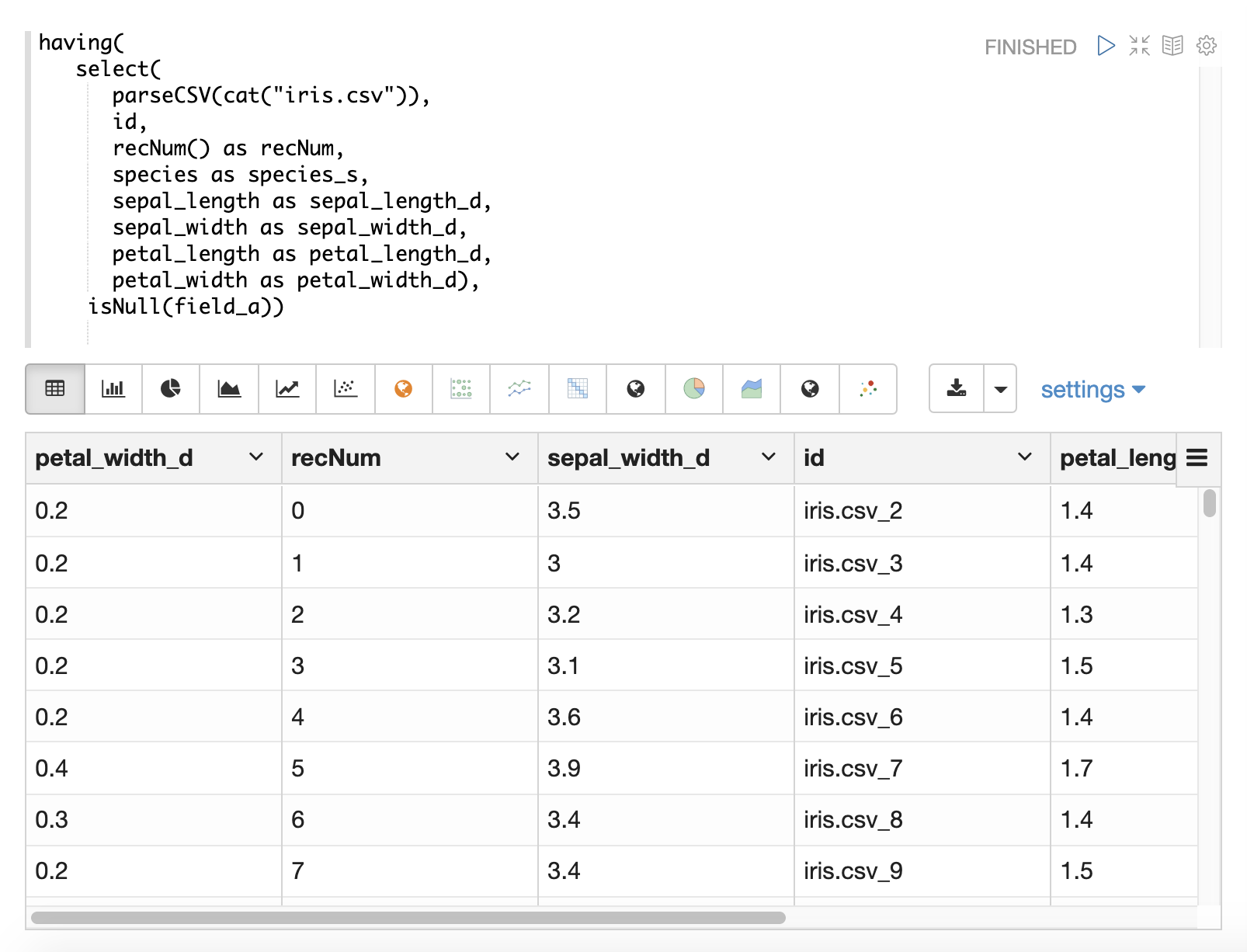
支援以下布林函式:eq、gt、gteq、lt、lteq、matches、and、or、not、notNull、isNull。
以下是一些使用 having 函式篩選記錄的策略。
處理 Null 值
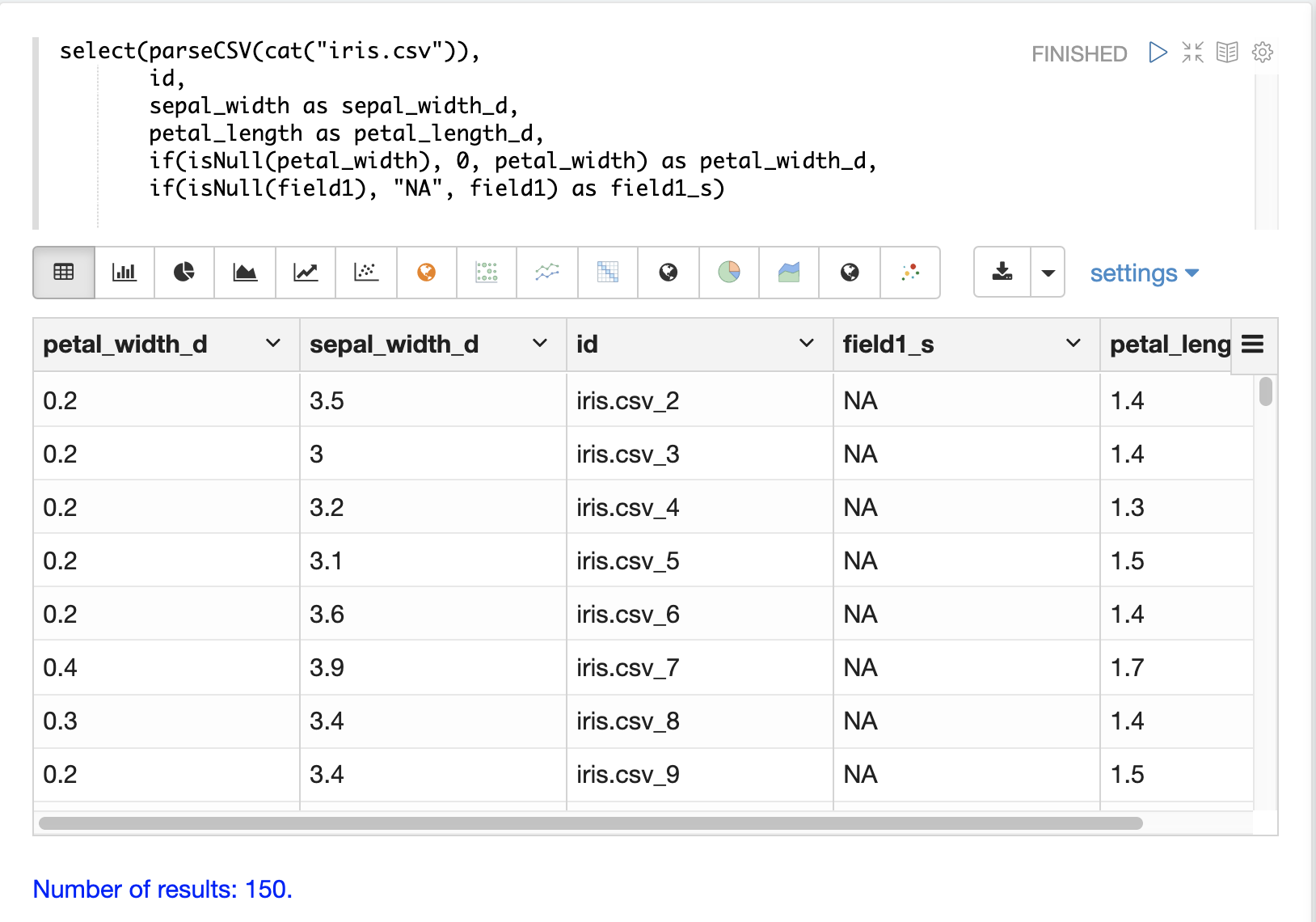
在大多數情況下,除非在載入期間需要特定的邏輯來處理 Null 值,否則不需要直接處理 Null 值。
select 函式不會輸出包含 Null 值的欄位。這表示當在資料中遇到 Null 值時,欄位不會包含在元組中。
如果字串操作函式遇到 Null 值,則都會傳回 Null 值。這表示 Null 值會傳遞到 select 函式,並且包含 Null 值的欄位將不會包含在記錄中。
在某些情況下,直接篩選或取代 Null 值可能很重要。以下章節將說明這些情況。

文字分析
analyze 函式可以在 select 函式內使用,以使用可用的分析器分析文字欄位。analyze 的輸出是一個已分析的符記清單,可以以多值欄位的方式新增至每個元組。
然後,多值欄位可以傳送到 Solr 以建立索引,或者可以使用 cartesianProduct 函式將符記清單擴充為元組串流。
analyze 函式有許多有趣的用例
-
在建立索引之前預覽不同分析器的輸出。
-
在文件到達索引管道之前,使用 NLP 產生的符記(實體擷取、名詞詞組等)來註解文件。這會將繁重的 NLP 處理從也可能正在處理查詢的伺服器中移除。它也允許將更多計算資源應用於 NLP 索引,而不是在搜尋叢集上可用的資源。
-
使用
cartesianProduct函式,已分析的符記可以索引為個別文件,這允許使用 Solr 的彙總和圖形運算式來搜尋和分析已分析的符記。 -
同樣,使用
cartesianProduct,已分析的符記可以使用串流運算式直接在建立索引之前進行彙總、分析和視覺化。
以下是在元組中的 Resolution.Description 欄位套用 analyze 函式的範例。使用 _text_ 欄位分析器來分析文字,並且已分析的符記會新增至 token_ss 欄位中的文件。
select(parseCSV(cat("yr2017.csv", maxLines="2")),
Resolution.Description,
analyze(Resolution.Description, _text_) as tokens_ss)當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"Resolution.Description": "The Department of Health and Mental Hygiene will review your complaint to determine appropriate action. Complaints of this type usually result in an inspection. Please call 311 in 30 days from the date of your complaint for status",
"tokens_ss": [
"department",
"health",
"mental",
"hygiene",
"review",
"your",
"complaint",
"determine",
"appropriate",
"action",
"complaints",
"type",
"usually",
"result",
"inspection",
"please",
"call",
"311",
"30",
"days",
"from",
"date",
"your",
"complaint",
"status"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}以下範例顯示了 cartesianProduct 函式將 term_s 欄位中已分析的詞彙擴充到它們自己的文件中。請注意,文件中其他欄位會與每個詞彙一起維護。這允許每個詞彙在個別文件中建立索引,因此可以透過圖形運算式或彙總來探索詞彙和其他欄位之間的關係。
