文字分析和詞向量
本節使用者指南概述了數學運算式中的文字分析、文字分析和 TF-IDF 詞向量函式。
文字分析
analyze 函式將 Solr 分析器套用到文字欄位,並在陣列中傳回分析器發出的語彙單元。Solr 結構描述中附加到欄位的任何分析器鏈都可以與 analyze 函式搭配使用。
在下面的範例中,文字 "hello world" 會使用附加到結構描述中 subject 欄位的分析器鏈進行分析。subject 欄位定義為欄位類型 text_general,並使用為 text_general 欄位類型設定的分析鏈來分析文字。
analyze("hello world", subject)當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"return-value": [
"hello",
"world"
]
},
{
"EOF": true,
"RESPONSE_TIME": 0
}
]
}
}註解文件
analyze 函式可用於 select 函式內部,以使用分析產生的語彙單元來註解文件。
以下範例會在 "collection1" 中執行 search。search 函式傳回的每個元組都包含 id 和 subject。針對每個元組,select 函式會選取 id 欄位,並對 subject 欄位呼叫 analyze 函式。由 subject_bigram 欄位指定的分析器鏈設定為執行二元語法分析。由 analyze 函式產生的語彙單元會新增至每個元組中的名為 terms 的欄位。
select(search(collection1, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms)請注意,在輸出中,二元語法詞彙的陣列已新增至元組
{
"result-set": {
"docs": [
{
"terms": [
"text analysis",
"analysis example"
],
"id": "1"
},
{
"terms": [
"example number",
"number two"
],
"id": "2"
},
{
"EOF": true,
"RESPONSE_TIME": 4
}
]
}
}文字分析
cartesianProduct 函式可以與 analyze 函式結合使用,以執行各種文字分析。
cartesianProduct 函式會將多值欄位擴展為元組串流。當使用 analyze 函式建立多值欄位時,cartesianProduct 函式會將分析過的語彙單元擴展為元組串流。這允許對分析過的語彙單元串流執行分析,並使用 Zeppelin-Solr 將結果視覺化。
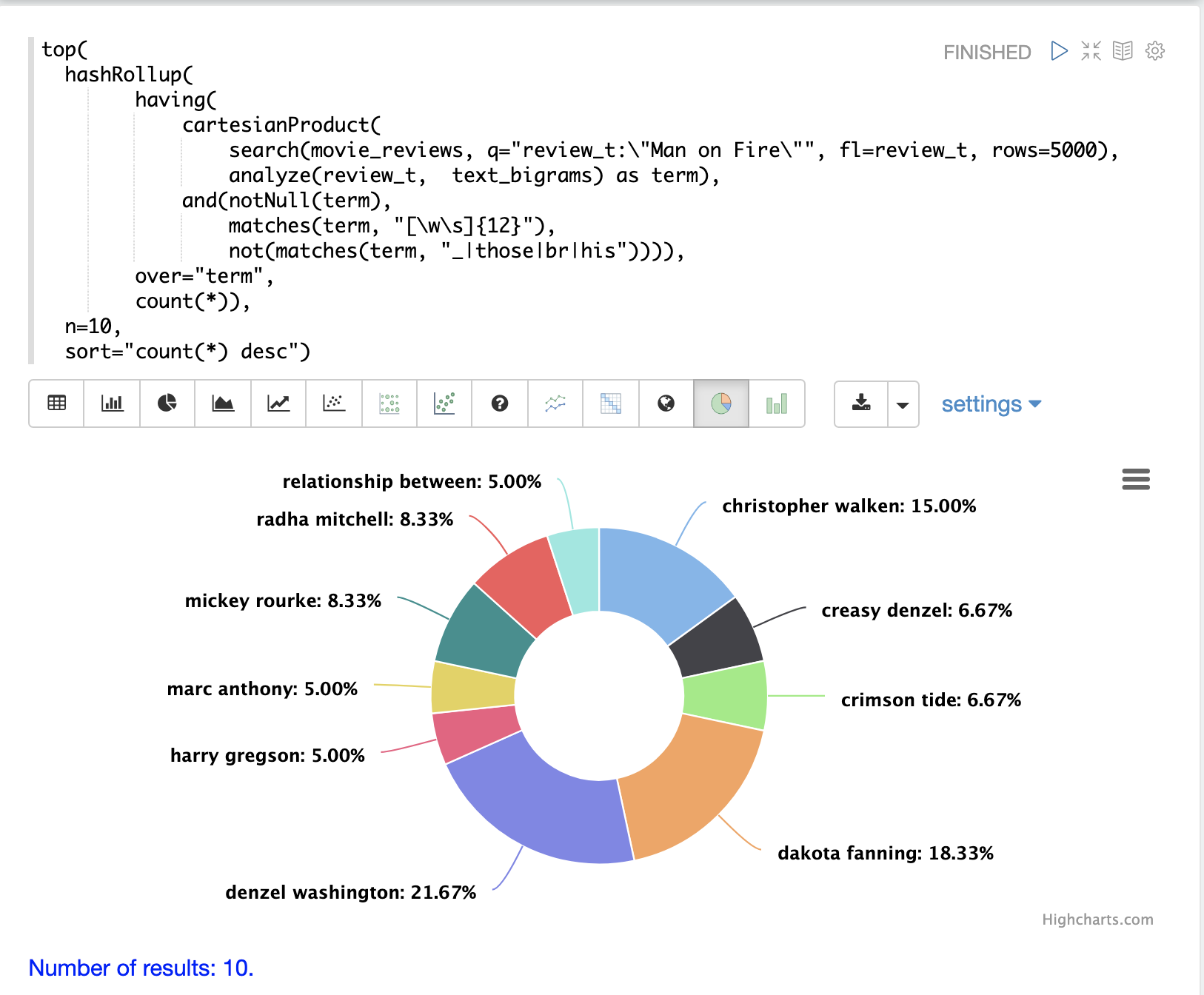
範例:片語彙總
執行片語彙總的範例用於說明結合 cartesianProduct 和 analyze 的威力。
在此範例中,search 運算式是在電影評論集合上執行的。搜尋片語查詢 "Man on Fire",並傳回依分數排序的前 5000 個結果。從結果中傳回單一欄位,即包含電影評論文字的 review_t 欄位。
然後,cartesianProduct 函式會在搜尋結果上執行。cartesianProduct 函式會套用 analyze 函式,此函式會採用 review_t 欄位,並使用附加到 text_bigrams 結構描述欄位的分析器進行分析。此分析器會發出在文字欄位中找到的二元語法。cartesianProduct 函式會將每個二元語法擴展到其自己的元組中,並將二元語法儲存在 term 欄位中。
然後,使用規則運算式透過 having 函式篩選元組串流,以選取長度為 12 或更大的二元語法,並篩選出包含特定字元的二元語法。
接著,hashRollup 函數會彙總 bigram,而 top 函數則會依計數發出前 10 個 bigram。
然後,使用 Zeppelin-Solr 來視覺化前 10 個 bigram。
分析器可以透過多種不同的方式進行配置,以支援對 NLP 實體(人物、地點、公司等)以及使用正規表示式或字典提取的 token 進行彙總。
TF-IDF 詞向量
可以使用 termVectors 函數,從 analyze 函數產生的詞彙建立 TF-IDF 詞向量。
termVectors 函數會對包含一個名為 id 的欄位和一個名為 terms 的欄位的元組列表進行操作。請注意,這與上述文件註解範例的輸出結構完全相同。
termVectors 函數會從元組列表建立一個矩陣。矩陣中每一列對應於列表中的每個元組。矩陣中每一行對應於 terms 欄位中的每個詞彙。
let(echo="c, d", (1)
a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"), (2)
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1), (3)
c=getRowLabels(b), (4)
d=getColumnLabels(b))下面的範例基於文件註解範例。
| 1 | echo 參數會回顯變數 c 和 d,因此輸出會包含列和行的標籤,這些標籤將在稍後的運算式中定義。 |
| 2 | 元組列表會儲存在變數 a 中。termVectors 函數會對變數 a 進行操作,並建立一個具有 2 列和 4 行的矩陣。 |
| 3 | termVectors 函數會將詞向量矩陣的列和行標籤設定為變數 b。列標籤是文件 ID,行標籤是詞彙。 |
| 4 | getRowLabels 和 getColumnLabels 函數會傳回列和行的標籤,然後將其儲存在變數 c 和 d 中。 |
當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"c": [
"1",
"2"
],
"d": [
"analysis example",
"example number",
"number two",
"text analysis"
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}TF-IDF 值
詞向量矩陣內的值是每個文件中每個詞彙的 TF-IDF 值。下面的範例顯示了矩陣的值。
let(a=select(search(collection3, q="*:*", fl="id, subject", sort="id asc"),
id,
analyze(subject, subject_bigram) as terms),
b=termVectors(a, minTermLength=4, minDocFreq=0, maxDocFreq=1))當此運算式傳送到 /stream 處理器時,它會回應
{
"result-set": {
"docs": [
{
"b": [
[
1.4054651081081644,
0,
0,
1.4054651081081644
],
[
0,
1.4054651081081644,
1.4054651081081644,
0
]
]
},
{
"EOF": true,
"RESPONSE_TIME": 5
}
]
}
}限制雜訊
在使用詞向量時,其中一個關鍵挑戰是文字通常具有大量的雜訊,這些雜訊會模糊資料中的重要詞彙。termVectors 函數有幾個參數旨在過濾掉不太有意義的詞彙。這也很重要,因為消除雜訊詞彙有助於保持詞向量矩陣足夠小,以便舒適地放入記憶體中。
有四個參數旨在從詞向量矩陣中過濾掉雜訊詞彙
minTermLength-
選用
預設值:
3將詞彙包含在矩陣中所需的最小詞彙長度。
minDocFreq-
選用
預設值:
.05詞彙必須出現在索引中,所必須出現的文件最小百分比,表示為
0到1之間的數字。 maxDocFreq-
選用
預設值:
.5詞彙可以出現在索引中,所允許出現的文件最大百分比,表示為
0到1之間的數字。 exclude-
選用
預設值:無
用逗號分隔的字串列表,用於排除詞彙。如果詞彙包含任何排除的字串,則該詞彙將會從詞向量中排除。