結果分群
|
分群元件實作和 API(參數)在 9.0 版中已大幅變更。請參考與您的 Solr 版本完全相符的 Solr 指南。 |
分群(或集群分析)外掛程式嘗試自動探索相關搜尋結果(文件)的群組,並為這些群組指派人類可讀取的標籤。
Solr 中的分群演算法會應用於每個單一查詢搜尋結果中包含的文件 - 這稱為線上分群。
針對給定查詢探索到的群組可以被視為動態分面。當一般分面困難(欄位值事先未知)或查詢本質上是探索性的時,這會很有幫助。請查看 Carrot2 專案的示範頁面,以查看實際搜尋結果分群的範例(視覺化中的群組已在右側的搜尋結果中自動探索,不涉及外部資訊)。
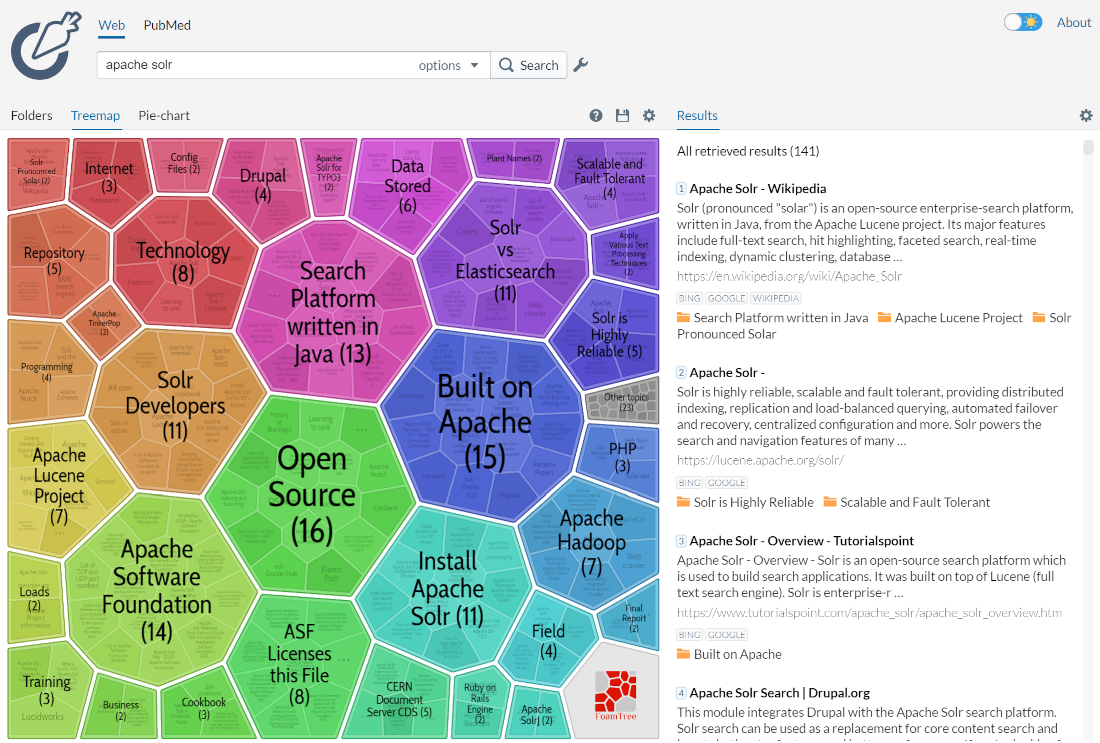
發送給系統的查詢是Apache Solr。很明顯,分面無法產生類似的群組集合,儘管這兩種技術的目標相似 - 讓使用者探索搜尋結果集合,並重新組織查詢或將焦點縮小到目前文件的子集。分群也類似於結果分組,它可以幫助深入了解搜尋結果,而不僅僅是前幾個結果。
模組
這透過 clustering Solr 模組提供,使用前需要啟用。
設定快速入門
分群擴充功能作為搜尋元件運作。它需要在 solrconfig.xml 中宣告和設定,例如
<searchComponent class="org.apache.solr.handler.clustering.ClusteringComponent" name="clustering">
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.fields">title, content</str>
<str name="clustering.algorithm">Lingo</str>
</lst>
</searchComponent>以上宣告了具有單一引擎的分群元件 - 可以宣告多個引擎並在執行時切換。我們稍後會回到如何設定引擎的詳細資訊。
分群元件必須附加到 SearchHandler,並透過屬性 clustering 明確啟用。請務必將其附加為處理器管道中的最後一個元件,如下所示
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<bool name="clustering">true</bool>
<str name="clustering.engine">lingo</str>
</lst>
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>一旦附加(如以上範例所示),分群將在所有符合搜尋處理器查詢的文件上自動執行。分群擴充功能將考量引擎的 clustering.fields 參數中列出的所有文字欄位,並產生一個名為 clusters 的回應區段,其中包含探索到的群組結構,例如(JSON 回應為簡潔起見)
{
"clusters": [
{
"labels": ["Memory"],
"score": 6.80,
"docs":[ "0579B002",
"EN7800GTX/2DHTV/256M",
"TWINX2048-3200PRO",
"VDBDB1A16",
"VS1GB400C3"]},
{
"labels":["Coins and Notes"],
"score":28.560285143284457,
"docs":["EUR",
"GBP",
"NOK",
"USD"]},
{
"labels":["TFT LCD"],
"score":15.355729924203429,
"docs":["3007WFP",
"9885A004",
"MA147LL/A",
"VA902B"]}
]
}每個叢集的 labels 元素是一個動態探索到的短語,描述並適用於 docs 元素下的所有文件識別碼。
Solr 發行範例
Solr 隨附的「techproducts」範例已預先設定所有必要的結果分群元件 - 但預設為停用。
若要啟用分群元件擴充功能以及設定為使用它的專用搜尋處理器,請在執行範例時指定 JVM 系統屬性
bin/solr start -e techproducts -Dsolr.clustering.enabled=true您現在可以透過在瀏覽器中開啟下列 URL 來試用分群處理器
https://127.0.0.1:8983/solr/techproducts/clustering?q=*:*&rows=100&wt=xml
輸出 XML 應包含搜尋結果,最後還有一個自動探索到的群組陣列,類似於此處顯示的輸出
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">299</int>
</lst>
<result name="response" numFound="32" start="0" maxScore="1.0">
<doc>
<str name="id">GB18030TEST</str>
<str name="name">Test with some GB18030 encoded characters</str>
<arr name="features">
<str>No accents here</str>
<str>这是一个功能</str>
<str>This is a feature (translated)</str>
<str>这份文件是很有光泽</str>
<str>This document is very shiny (translated)</str>
</arr>
<float name="price">0.0</float>
<str name="price_c">0,USD</str>
<bool name="inStock">true</bool>
<long name="_version_">1448955395025403904</long>
<float name="score">1.0</float>
</doc>
<!-- more search hits, omitted -->
</result>
<arr name="clusters">
<lst>
<arr name="labels">
<str>DDR</str>
</arr>
<double name="score">3.9599865057283354</double>
<arr name="docs">
<str>TWINX2048-3200PRO</str>
<str>VS1GB400C3</str>
<str>VDBDB1A16</str>
</arr>
</lst>
<lst>
<arr name="labels">
<str>iPod</str>
</arr>
<double name="score">11.959228467119022</double>
<arr name="docs">
<str>F8V7067-APL-KIT</str>
<str>IW-02</str>
<str>MA147LL/A</str>
</arr>
</lst>
<!-- More clusters here, omitted. -->
<lst>
<arr name="labels">
<str>Other Topics</str>
</arr>
<double name="score">0.0</double>
<bool name="other-topics">true</bool>
<arr name="docs">
<str>adata</str>
<str>apple</str>
<str>asus</str>
<str>ati</str>
<!-- other unassigned document IDs here -->
</arr>
</lst>
</arr>
</response>針對此查詢 (*:*) 發現了一些叢集,將所有搜尋結果區分為不同類別:DDR、iPod、硬碟等。每個叢集都有一個標籤和分數,表示該叢集的「優良程度」。分數是特定於演算法的,並且僅在同一組中其他叢集的分數之間才有意義。換句話說,如果叢集 A 的分數高於叢集 B,則叢集 A 的品質應該更好(具有更好的標籤和/或更一致的文件集)。每個叢集都有一組屬於它的文件識別碼。這些識別碼對應於 schema 中宣告的 uniqueKey 欄位。
有時叢集標籤可能沒有太大意義(這取決於許多因素 — 叢集欄位中的文字、文件數量、演算法參數)。此外,某些文件可能會被遺漏,根本不會被叢集;這些文件將被分配到合成的其他主題群組,並以 other-topics 屬性設定為 true 來標記(有關範例,請參閱上面的 XML 轉儲)。其他主題群組的分數為零。
組態
元件組態
以下屬性控制 ClusteringComponent 的狀態。
clustering-
選填
預設值:
false即使已正確宣告並附加到搜尋處理常式,該元件預設也會停用。必須將
clustering屬性設定為true才能啟用它。這可以透過在搜尋處理常式中設定預設參數來完成,如下一節所述。 clustering.engine-
選填
預設值:請參閱說明
宣告要使用的引擎。如果不存在,則使用第一個宣告的活動引擎。
叢集引擎
solrconfig.xml 中叢集元件的宣告必須包含一個或多個預先定義的組態,稱為引擎。例如,考慮下面的組態
<searchComponent class="org.apache.solr.handler.clustering.ClusteringComponent" name="clustering">
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">title, content</str>
</lst>
<lst name="engine">
<str name="name">stc</str>
<str name="clustering.algorithm">STC</str>
<str name="clustering.fields">title</str>
</lst>
</searchComponent>這宣告了兩個單獨的引擎(lingo 和 stc):這些組態具有不同的叢集演算法和一組不同的叢集文件欄位。可以透過在執行時(透過 URL)或在搜尋處理常式的組態中,傳遞 clustering.engine=name 參數來選擇活動引擎,如下所示
<requestHandler name="/clustering" class="solr.SearchHandler">
<lst name="defaults">
<!-- Clustering component enabled. -->
<bool name="clustering">true</bool>
<str name="clustering.engine">stc</str>
<!-- Cluster the top 100 search results - bump up the 'rows' parameter. -->
<str name="rows">100</str>
</lst>
<!-- Append clustering at the end of the list of search components. -->
<arr name="last-components">
<str>clustering</str>
</arr>
</requestHandler>叢集引擎組態參數
可以使用下面描述的許多參數來組態每個宣告的引擎。
clustering.fields-
必填
預設值:無
以逗號(或空格)分隔的文字欄位清單,其中應包含用於叢集的文字內容。必須至少提供一個欄位。這些欄位與搜尋處理常式的
fl參數分開,因此叢集欄位不必包含在回應中。 clustering.algorithm-
必填
預設值:無
叢集演算法是發現文件之間關係並形成人類可讀的叢集標籤的實際邏輯(實作)。此參數設定此引擎將使用的叢集演算法名稱。演算法透過 Carrot2 定義的服務擴充功能提供給 Solr。預設情況下,應提供以下開放原始碼演算法:
Lingo、STC、Bisecting K-Means。如果類別路徑上可用,則商業叢集演算法Lingo3G會插入同一個擴充點並且可以使用。
clustering.maxLabels-
選填
預設值:無
返回的叢集標籤最大數量(如果演算法返回更多標籤,則列表將被截斷)。預設情況下,返回所有標籤。
clustering.includeSubclusters-
選填
預設值:無
如果為
true,則回應中會包含支援階層式叢集演算法的子叢集。false僅返回頂層叢集。 clustering.includeOtherTopics-
選填
預設值:
true如果為
true,則會形成並返回一個名為其他主題的合成叢集,其中包含所有未分配給任何其他叢集的文件。如果不需要此合成叢集,則可以將其設定為false。 clustering.resources-
選填
預設值:無
演算法特定資源和組態檔案(停止字詞、其他詞彙資源、預設設定)的位置。此屬性預設為
null,並且所有資源都從其各自的演算法預設資源池(JAR)讀取。如果此屬性不為空,則會相對於 Solr 核心的組態目錄解析。此參數只能在 Solr 啟動期間套用,不能按請求覆寫。
還有更多適用於引擎組態的屬性。我們將在後續的功能章節中描述這些屬性。
完整欄位和查詢內容 (程式碼片段) 叢集
叢集演算法可以使用欄位的完整內容,或僅使用查詢比對區域周圍的左側和右側內容(所謂的程式碼片段)。與直覺相反,即使向演算法提供較少的資料,使用查詢內容也可以提高叢集的品質。這通常是由於程式碼片段更集中在查詢周圍的片語和詞彙,並且演算法具有更好的資料訊號雜訊比可供使用。
我們建議當欄位包含大量內容時使用查詢內容(這會影響叢集效能)。
以下三個屬性控制是否處理內容或完整內容,以及如何形成用於叢集的程式碼片段。
clustering.preferQueryContext-
選填
預設值:無
如果為
true,則引擎會嘗試擷取查詢比對區域周圍的內容,並將這些內容用作叢集演算法的輸入。 clustering.contextSize-
選填
預設值:無
內容擷取演算法(內部螢光筆)建立的每個程式碼片段的最大大小(以字元為單位)。
clustering.contextCount-
選填
預設值:無
單一欄位中不同、非連續程式碼片段的最大數量。
預設叢集語言
Carrot2 中叢集演算法的預設實作(與 Solr 一起提供)具有內建支援(詞幹、停止字詞)來預處理許多語言。重要的是為叢集演算法提供一個關於叢集應使用哪種語言的提示。這可以透過兩種方式完成 — 傳遞預設語言的名稱或為每個文件提供一個帶有語言的欄位。以下兩個引擎組態參數控制此項
clustering.language-
選填
預設值:
English用於叢集的預設語言名稱。提供的語言必須可用,並且叢集演算法必須支援它。
clustering.languageField-
選填
預設值:無
儲存文件語言的文件欄位名稱。如果文件不存在該欄位或值為空白,則使用預設語言。
支援語言的清單可以動態變更(語言透過外部服務提供者擴充功能載入),並且可能取決於所選的演算法(演算法可以支援資源可用的語言子集)。叢集元件會在 Solr 啟動時記錄所有支援的演算法語言對,因此您可以檢查您的特定 Solr 執行個體上支援的內容。例如
2020-10-29 [...] Clustering algorithm Lingo3G loaded with support for the following languages: Dutch, English
2020-10-29 [...] Clustering algorithm Lingo loaded with support for the following languages: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish
2020-10-29 [...] Clustering algorithm Bisecting K-Means loaded with support for the following languages: Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish, Swedish, Turkish調整演算法設定
Solr 隨附的叢集演算法使用其預設參數值和語言資源。我們強烈建議針對生產用途進行調整。改進預設語言資源以包含特定文件網域常用的字詞和片語將顯著提高叢集品質。
Carrot2 演算法具有廣泛的參數和語言資源調整選項。請參閱 最新專案文件。特別是語言資源部分和每個演算法的屬性部分。
變更叢集演算法參數
叢集演算法設定可以透過 Solr 參數永久變更(在引擎宣告中)或按請求變更(透過 Solr URL 參數)。
例如,假設有以下引擎組態
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
</lst>首先,在 Carrot2 文件網站上找到 Lingo 演算法的組態參數
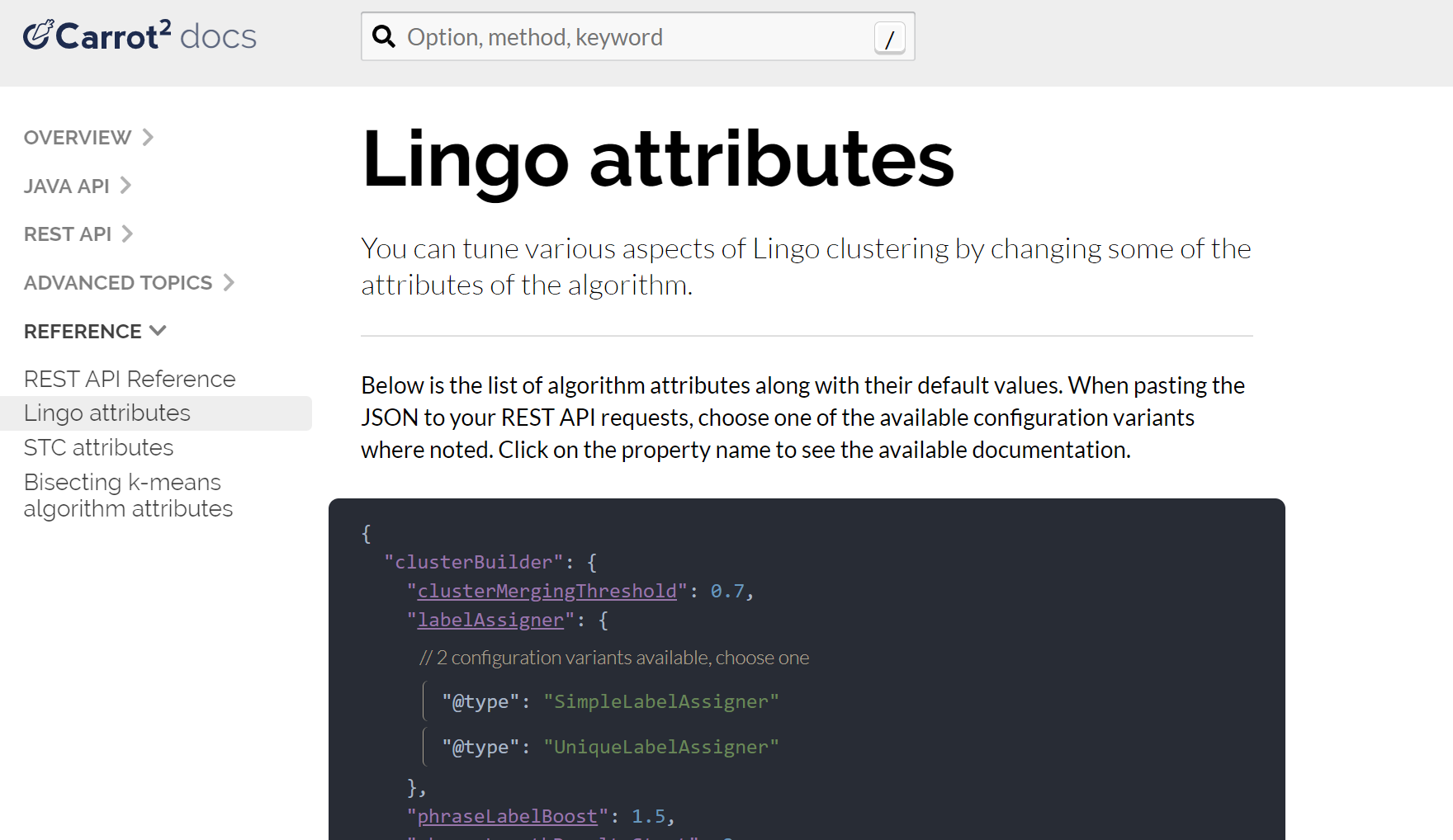
然後找到您要變更的特定設定,並記下該設定的 REST API 路徑(在此情況下,參數為 minClusterSize,其路徑為 preprocessing.documentAssigner.minClusterSize)

現在將完整的路徑值配對新增至引擎的組態中
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
<int name="preprocessing.documentAssigner.minClusterSize">3</int>
</lst>以下規則適用。
-
參數的類型必須與 Carrot2 規格中列出的類型一致。
-
如果參數是在
solrconfig.xml中新增至引擎的組態,則必須重新載入核心,變更才會生效。或者,透過請求 URL 傳遞參數,以在每個請求的基礎上動態變更設定。例如,如果您正在執行「techproducts」範例,這將會將叢集縮減為僅包含至少三個文件的叢集:https://127.0.0.1:8983/solr/techproducts/clustering?q=*:*&rows=100&wt=json&preprocessing.documentAssigner.minClusterSize=3 -
對於複雜類型,具有實例化類型名稱的參數鍵必須先於其任何自身的參數。
自訂語言資源
叢集演算法依賴於語言和特定領域的語言資源,以提高叢集的品質(透過捨棄特定領域的雜訊和樣板語言)。
預設情況下,語言資源是從引擎宣告的演算法預設 JAR 讀取。您可以透過指定 clustering.resources 參數來傳遞這些資源的自訂位置。此參數的值會解析為相對於 Solr 核心組態目錄的位置。例如,以下定義
<lst name="engine">
<str name="name">lingo</str>
<str name="clustering.algorithm">Lingo</str>
<str name="clustering.fields">name, features</str>
<str name="clustering.language">English</str>
<str name="clustering.resources">lingo-resources</str>
</lst>將產生以下記錄項目和預期的資源位置
Clustering algorithm resources first looked up relative to: [.../example/techproducts/solr/techproducts/conf/lingo-resources]開始調整演算法資源的最佳方式是從其對應的 Carrot2 JAR 檔案(或 Carrot2 發行版本)複製所有預設值。
效能考量
搜尋結果的叢集化會帶來一些效能考量
-
擷取大於平常數量的搜尋結果(50、100 或更多文件)的成本,
-
叢集化本身的額外計算成本。
-
在分散式模式下,用於叢集化的文件欄位內容是從分片收集的,這會增加一些額外的網路負擔。
對於簡單的查詢,叢集化時間通常會佔據其他所有時間。如果文件欄位非常長,則檢索儲存的內容可能會成為瓶頸。
可以透過幾種方式降低叢集化對效能的影響。
-
減少叢集化的資料:使用查詢內容(程式碼片段)而不是完整的欄位內容 (
clustering.preferQueryContext=true)。 -
僅對部分文件欄位執行叢集化,或者為叢集化管理欄位(在建立索引時新增摘要),以縮減輸入大小。
-
調整直接與特定演算法相關的效能屬性。
-
嘗試使用不同的、更快的演算法(STC 而非 Lingo,Lingo3G 而非 STC)。
其他資源
以下資源提供了有關 Solr 中叢集元件及其潛在應用程式的更多資訊。
-
Solr 搜尋結果的叢集化與視覺化 (Berlin BuzzWords 會議,2011):http://2011.berlinbuzzwords.de/sites/2011.berlinbuzzwords.de/files/solr-clustering-visualization.pdf