索引段與合併
Lucene 索引儲存在段中,而 Solr 提供數個參數來控制如何寫入新段以及何時合併段。
Lucene 索引是「寫入一次」的檔案:一旦將一個段寫入永久儲存空間(到磁碟),就永遠不會被修改。這表示索引實際上是由多個檔案組成,每個檔案都是完整索引的子集。為了防止索引永久分散,段會定期合併。
solrconfig.xml 中的 <indexConfig>
solrconfig.xml 的 <indexConfig> 區段定義 Lucene 索引寫入器的低階行為。
預設情況下,設定會註解在 Solr 隨附的範例 solrconfig.xml 中,這表示會使用預設值。在大多數情況下,預設值是沒問題的。
<indexConfig>
...
</indexConfig>寫入新段
以下元素可以在 <indexConfig> 元素下定義,並定義何時將新段寫入(「刷新」)到磁碟。
ramBufferSizeMB
一旦累積的文件更新超過此記憶體空間(以 MB 為單位定義),就會刷新待處理的更新。這也會建立新段或觸發合併。一般來說,使用此設定比使用 maxBufferedDocs 更佳。如果 solrconfig.xml 中同時設定了 maxBufferedDocs 和 ramBufferSizeMB,則當達到其中一個限制時,就會發生刷新。預設值為 100 MB。
<ramBufferSizeMB>100</ramBufferSizeMB>合併索引段
以下設定定義何時合併段。
mergePolicyFactory
定義如何合併段落 (segment)。
Solr 的預設值是使用 TieredMergePolicy,它會合併大小大致相同的段落,並遵守每個層級允許的段落數量。
其他可用的策略包括 LogByteSizeMergePolicy 和 LogDocMergePolicy。如需這些策略的更多資訊,請參閱 MergePolicy 的 javadoc。
<mergePolicyFactory class="org.apache.solr.index.TieredMergePolicyFactory">
<int name="maxMergeAtOnce">10</int>
<int name="segmentsPerTier">10</int>
<double name="forceMergeDeletesPctAllowed">10.0</double>
<double name="deletesPctAllowed">33.0</double>
</mergePolicyFactory>控制段落大小
使用者對 TieredMergePolicy (或 LogByteSizeMergePolicy) 設定進行最常見的調整是「合併因子」,用以變更一次應合併多少個段落,以及在 TieredMergePolicy 的情況下,變更合併後的段落最大大小。
對於 TieredMergePolicy,這是透過設定 maxMergeAtOnce (預設值為 10)、segmentsPerTier (預設值為 10) 和 maxMergedSegmentMB (預設值為 5000) 選項來控制的。
LogByteSizeMergePolicy 具有單一的 mergeFactor 選項 (預設值為 10)。
若要了解這些選項為何重要,請考慮當使用 LogByteSizeMergePolicy 更新索引時會發生什麼情況:文件始終會新增至最近開啟的段落。當段落填滿時,會建立新的段落,後續的更新會放置在那裡。
如果建立新的段落會導致最低層級的段落數量超過 mergeFactor 值,則所有這些段落會合併在一起,形成一個較大的單一段落。因此,如果合併因子為 10,則每次合併都會建立一個單一段落,其大小大約是其十個組成部分中的每一個的十倍。當有 10 個較大的段落時,它們又會合併成一個更大的單一段落。這個過程可以無限期地繼續下去。
當使用 TieredMergePolicy 時,過程相同,但不是使用單一的 mergeFactor 值,而是使用 segmentsPerTier 設定作為決定是否應進行合併的閾值,而 maxMergeAtOnce 設定則決定應在合併中包含多少個段落。
選擇最佳的合併因子通常是在索引速度與搜尋速度之間進行權衡。索引中的段落越少,通常可以加快搜尋速度,因為要搜尋的地方就越少。它也可以減少磁碟上的實體檔案數量。但是,為了保持段落數量較少,合併會更頻繁地發生,這可能會增加系統的負載並減慢索引的更新速度。
相反地,保留更多的段落可以加快索引速度,因為合併發生的頻率較低,這表示更新不太可能觸發合併。但是,搜尋會變得更耗費計算資源,而且可能會變慢,因為必須在更多索引段落中查找搜尋詞彙。更快的索引更新也意味著更短的提交周轉時間,這意味著可以獲得更即時的搜尋結果。
控制已刪除文件的百分比
當文件被刪除或更新時,該文件會被標記為已刪除,但在段落合併之前,不會從索引中刪除。使用預設 TieredMergePolicy 時,可以調整兩個參數,這些參數會影響索引中已刪除文件的數量。
forceMergeDeletesPctAllowed-
選填
預設值:
10.0當發出外部
expungeDeletes命令時,任何已刪除文件超過此百分比的段落都會合併到新的段落中,且與已刪除文件相關的資料將被清除。值為0.0會使 expungeDeletes 的行為與optimize完全相同。 deletesPctAllowed-
選填
預設值:
33.0在正常的段落合併期間,會盡最大努力確保索引中已刪除文件的總百分比低於此閾值。有效設定介於 20% 到 50% 之間。選擇 33% 作為預設值的原因是,當此設定接近 20% 時,會為系統增加相當大的負載。
自訂合併策略
如果內建合併策略的設定選項不完全符合您的使用案例,您可以自訂它們,方法是建立在設定中指定的自訂合併策略工廠,或設定 合併策略封裝器,其使用 wrapped.prefix 設定選項來控制其封裝的工廠的設定方式。
<mergePolicyFactory class="org.apache.solr.index.SortingMergePolicyFactory">
<str name="sort">timestamp desc</str>
<str name="wrapped.prefix">inner</str>
<str name="inner.class">org.apache.solr.index.TieredMergePolicyFactory</str>
<int name="inner.maxMergeAtOnce">10</int>
<int name="inner.segmentsPerTier">10</int>
</mergePolicyFactory>上面的範例顯示 Solr 的 SortingMergePolicyFactory 被設定為依 "timestamp desc" 對合併段落中的文件進行排序,並封裝在 TieredMergePolicyFactory 周圍,該工廠設定為透過 SortingMergePolicyFactory 的 wrapped.prefix 選項定義的 inner 前綴使用值 maxMergeAtOnce=10 和 segmentsPerTier=10。如需有關使用 SortingMergePolicyFactory 的更多資訊,請參閱 segmentTerminateEarly 參數。
mergeScheduler
合併排程器控制如何執行合併。預設的 ConcurrentMergeScheduler 會使用單獨的執行緒在背景執行合併。另一種替代方案 SerialMergeScheduler 不會使用單獨的執行緒執行合併。
ConcurrentMergeScheduler 具有下列可設定的屬性。這些屬性的預設值會根據底層磁碟機是否為旋轉磁碟而動態設定。有關更多詳細資訊,請參閱 ConcurrentMergeScheduler 的動態預設值。
maxMergeCount-
選填
預設值:無
允許的最大並行合併數。如果需要合併,但我們已經有這麼多執行緒正在執行,則索引執行緒將會阻塞,直到合併執行緒完成為止。請注意,Solr 一次只會執行最小的
maxThreadCount合併。 maxThreadCount-
選填
預設值:無
應該同時執行的最大並行合併執行緒數。這必須小於
maxMergeCount。 ioThrottle-
選填
預設值:無
一個布林值 (
true或false),用於明確控制 I/O 節流。預設情況下,會啟用節流,且 CMS 在合併時會限制 I/O 輸送量,以便為其他 (搜尋、索引) 留出一些空間。
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/><mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler">
<int name="maxMergeCount">9</int>
<int name="maxThreadCount">4</int>
</mergeScheduler>mergedSegmentWarmer
當將 Solr 用於近乎即時使用案例時,可以設定合併的段落暖機器,以便在合併提交之前,對新合併的段落上的讀取器進行暖機。這對於近乎即時搜尋不是必需的,但會減少在合併完成後開啟新的近乎即時讀取器時的搜尋延遲。
<mergedSegmentWarmer class="org.apache.lucene.index.SimpleMergedSegmentWarmer"/>複合檔案段落
每個 Lucene 段落通常包含十幾個檔案。可以設定 Solr 將 Lucene 段落的所有檔案捆綁到單個複合檔案中,並使用 .cfs 的副檔名,代表「複合檔案段落」。
根據執行環境的不同,CFS 段落可能會因各種原因而產生輕微的效能損失。例如,檔案系統緩衝區通常與開啟的檔案描述符相關聯,這可能會限制每個索引可用的總快取空間。
在每個處理允許開啟的檔案數量有限制的系統上,CFS 可以避免達到該限制。也可以使用 Linux/Unix ulimit 命令調整作業系統的開啟檔案限制,或在其他作業系統上使用類似的命令。
|
CFS:新段落與合併段落
若要設定新寫入的段落是否應使用 CFS,請參閱上述 許多合併策略實作都支援 |
段落資訊畫面
管理 UI 中的「段落資訊」畫面可讓您查看此核心的底層 Lucene 索引中各個段落的可視化呈現,其中包含每個段落的大小資訊,包括位元組和文件數量,以及關於這些段落的其他基本中繼資料。最明顯的是已刪除文件的數量,但您可以將滑鼠懸停在段落上方以查看其他數值詳細資訊。
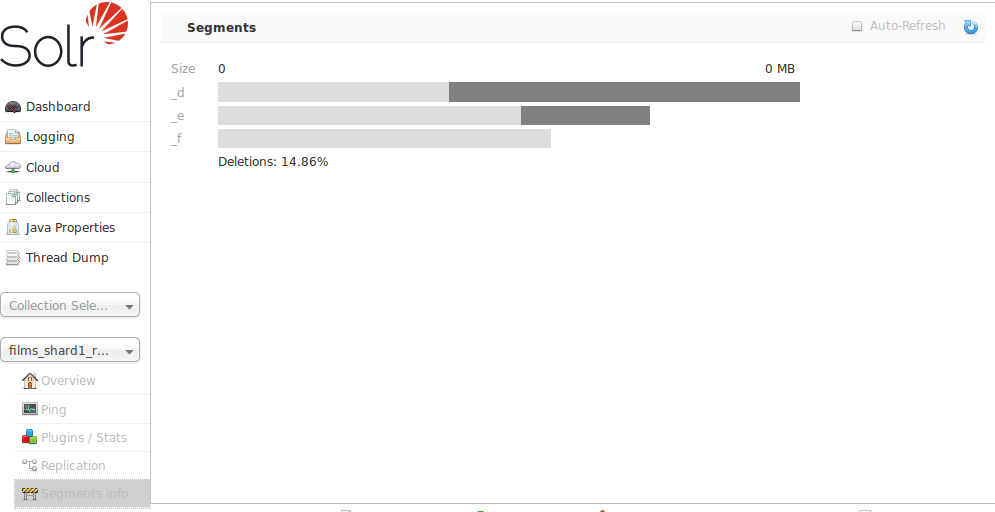
此資訊對於使用者來說,有助於他們決定資料的最佳合併設定。
索引鎖定
lockType
LockFactory 選項指定要使用的鎖定實作。
有效鎖定類型選項的集合取決於您設定的DirectoryFactory。
下面列出的值是 StandardDirectoryFactory (預設值) 支援的值
-
native(預設值) 使用NativeFSLockFactory指定原生作業系統檔案鎖定。如果第二個 Solr 處理嘗試存取該目錄,則會失敗。當多個 Solr Web 應用程式嘗試共用單個索引時,請勿使用。另請參閱 NativeFSLockFactory 的 javadoc。 -
simple使用SimpleFSLockFactory指定用於鎖定的純檔案。另請參閱 SimpleFSLockFactory 的 javadoc。 -
single(專家) 使用SingleInstanceLockFactory。適用於唯讀索引目錄的特殊情況,或者當不可能有多個處理程序嘗試修改索引時 (即使是循序)。此類型將防止同一 JVM 中的多個核心嘗試存取相同的索引。如果不同 JVM 中的多個 Solr 實例修改索引,則此類型不會防止索引損壞。 -
hdfs使用HdfsLockFactory來支援將索引和交易記錄檔讀取和寫入到 HDFS 檔案系統。有關使用此功能的更多詳細資訊,請參閱 Solr on HDFS 一節。
<lockType>native</lockType>其他索引設定
還有一些其他參數對於您的實作來說可能很重要。這些設定會影響索引的更新方式或時機。
deletionPolicy
控制在回滾的情況下如何保留提交。預設值為 SolrDeletionPolicy,它接受以下參數:
maxCommitsToKeep-
選填
預設值:無
要保留的最大提交次數。
maxOptimizedCommitsToKeep-
選填
預設值:無
要保留的最大最佳化提交次數。
maxCommitAge-
選填
預設值:無
要保留的任何提交的最大年齡。這支援
DateMathParser語法。
<deletionPolicy class="solr.SolrDeletionPolicy">
<str name="maxCommitsToKeep">1</str>
<str name="maxOptimizedCommitsToKeep">0</str>
<str name="maxCommitAge">1DAY</str>
</deletionPolicy>