練習 2:索引電影資料
練習 2:修改 Schema 並索引電影資料
本練習將以上一個練習為基礎,向您介紹索引 schema 和 Solr 強大的分面功能。
重新啟動 Solr
您在上一個練習後停止了 Solr 嗎? 沒有? 那麼請直接跳到下一節。
不過,如果您停止了,需要重新啟動 Solr,請發出以下命令
$ bin/solr start -c -p 8983 -s example/cloud/node1/solr這會啟動第一個節點。 完成後,啟動第二個節點,並告訴它如何連接到 ZooKeeper
$ bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983如果您已在 solr.in.sh/solr.in.cmd 中定義 ZK_HOST(請參閱 更新 Solr 包含檔案),則可以從上述命令中省略 -z <zk 主機字串>。 |
建立新的集合
我們將在本練習中使用全新的資料集,因此最好建立一個新的集合,而不是嘗試重複使用我們先前的集合。
這樣做的原因之一是我們將使用 Solr 中稱為「欄位猜測」的功能,Solr 會在索引欄位時嘗試猜測欄位中的資料類型。 它也會自動在 schema 中為傳入文件中出現的新欄位建立新欄位。 此模式稱為「無 Schema」。 我們將看到這種方法的優點和限制,以協助您決定在實際應用程式中如何以及在哪裡使用它。
當您在第一個練習中最初啟動 Solr 時,我們可以選擇要使用的 configset。我們選擇的 configset 具有預先針對我們稍後索引的資料定義的 schema。這次,我們將使用一個 schema 非常精簡的 configset,讓 Solr 從資料中自行判斷要新增哪些欄位。
您要索引的資料與電影相關,因此首先建立一個名為「films」的集合,該集合使用 _default configset。
$ bin/solr create -c films -s 2 -rf 2等等,我們沒有指定 configset!沒關係,_default 名副其實,因為它是預設值,如果您完全不指定,就會使用它。
不過,我們設定了兩個參數 -s 和 -rf。這些參數是將集合分割成的分片數 (2) 以及要建立的複本數 (2)。這相當於我們在第一個練習的互動範例中所擁有的選項。
您應該會看到類似以下的輸出:
WARNING: Using _default configset. Data driven schema functionality is enabled by default, which is
NOT RECOMMENDED for production use.
To turn it off:
bin/solr config -c films -p 7574 --action set-user-property --property update.autoCreateFields --value false
Connecting to ZooKeeper at localhost:9983 ...
INFO - 2017-07-27 15:07:46.191; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
Uploading /{solr-full-version}/server/solr/configsets/_default/conf for config films to ZooKeeper at localhost:9983
Creating new collection 'films' using command:
https://127.0.0.1:7574/solr/admin/collections?action=CREATE&name=films&numShards=2&replicationFactor=2&collection.configName=films
{
"responseHeader":{
"status":0,
"QTime":3830},
"success":{
"192.168.0.110:8983_solr":{
"responseHeader":{
"status":0,
"QTime":2076},
"core":"films_shard2_replica_n1"},
"192.168.0.110:7574_solr":{
"responseHeader":{
"status":0,
"QTime":2494},
"core":"films_shard1_replica_n2"}}}該指令列印的第一件事是警告,不建議在生產環境中使用此 configset。這是因為我們稍後會介紹的一些限制。
不過,除此之外,應該會建立該集合。如果我們前往管理介面 https://127.0.0.1:8983/solr/#/films/collection-overview,應該會看到概觀畫面。
為電影資料準備 Schemaless
使用 _default configset 附帶的 schema 時,會同時發生兩件事。
首先,我們使用的是「受管理 schema」,該 schema 設定為僅能由 Solr 的 Schema API 修改。這表示我們不應手動編輯它,以免混淆哪些編輯來自哪個來源。Solr 的 Schema API 可讓我們變更欄位、欄位類型及其他類型的 schema 規則。
其次,我們使用的是「欄位猜測」,這是在 solrconfig.xml 檔案中設定的 (並且包含 Solr 的大多數設定)。欄位猜測旨在讓我們開始使用 Solr 時,不必先定義我們認為會出現在文件中的所有欄位就可嘗試索引它們。這就是我們稱其為「schemaless」的原因,因為您可以快速開始並讓 Solr 在文件中遇到欄位時為您建立欄位。
聽起來很棒!嗯,其實不然,它有一些限制。它有點像是暴力破解,如果猜錯了,在索引資料之後,您無法對欄位進行太多變更,而必須重新索引。如果我們只有幾千個文件,那可能還好,但如果您有數百萬個文件,甚至更糟的是,無法再存取原始資料,這就會是一個真正的問題。
基於這些原因,Solr 社群不建議在沒有您自己定義的 schema 的情況下進入生產環境。我們指的是 schemaless 功能可以先使用,但您仍應確保您的 schema 符合您對資料索引方式以及使用者將如何查詢資料的期望。
可以將 schemaless 功能與已定義的 schema 混合使用。透過使用 Schema API,您可以定義幾個您知道想要控制的欄位,並讓 Solr 猜測其他不重要的欄位,或者您 (透過測試) 確信會猜測到您滿意的欄位。這就是我們在這裡要做的。
建立「names」欄位
我們將要索引的電影資料,每個電影都有少數幾個欄位:ID、導演姓名、電影名稱、上映日期和類型。
如果您查看 example/films 中的其中一個檔案,您會看到第一部電影名為 .45,於 2006 年上映。作為資料集中第一個文件,Solr 將根據記錄中的資料猜測欄位類型。如果我們繼續索引此資料,則第一個電影名稱會向 Solr 表示欄位類型是「浮點數」數字欄位,並建立一個類型為 FloatPointField 的「name」欄位。在此記錄之後的所有資料都必須是浮點數。
嗯,這樣行不通。我們有像 A Mighty Wind 和 Chicken Run 這樣的標題,它們是字串,絕對不是數字,也不是浮點數。如果我們讓 Solr 猜測「name」欄位是浮點數,稍後發生的是,其他標題會導致錯誤,並且索引會失敗。這樣做無法讓我們有任何進展。
我們可以在索引資料之前在 Solr 中設定「name」欄位,以確保 Solr 始終將其解譯為字串。在命令列中,輸入此 curl 命令:
$ curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' https://127.0.0.1:8983/solr/films/schema此命令使用 Schema API 來明確定義一個名為「name」的欄位,該欄位的欄位類型為「text_general」(文字欄位)。它不允許有多個值,但會被儲存 (表示可以透過查詢擷取)。
您也可以使用管理介面建立欄位,但它對欄位的屬性提供的控制權較少。不過,它對我們的案例來說足夠了。

建立「catchall」複製欄位
在開始索引之前,還需要進行一項變更。
在第一個練習中,當我們查詢已索引的文件時,我們不必指定要搜尋的欄位,因為我們使用的設定會將欄位複製到 text 欄位中,而且當查詢中沒有定義其他欄位時,該欄位是預設值。
我們現在使用的設定沒有該規則。我們需要為每個查詢定義要搜尋的欄位。不過,我們可以透過定義一個複製欄位來設定「catchall 欄位」,該欄位會從所有欄位中取得所有資料,並將其索引到名為 _text_ 的欄位中。現在就來做吧。
您可以使用管理介面或 Schema API 來執行此操作。
在命令列中,再次使用 Schema API 來定義複製欄位:
$ curl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" : {"source":"*","dest":"_text_"}}' https://127.0.0.1:8983/solr/films/schema在管理介面中,選擇 新增複製欄位,然後填寫欄位的來源和目的地,如下圖所示。
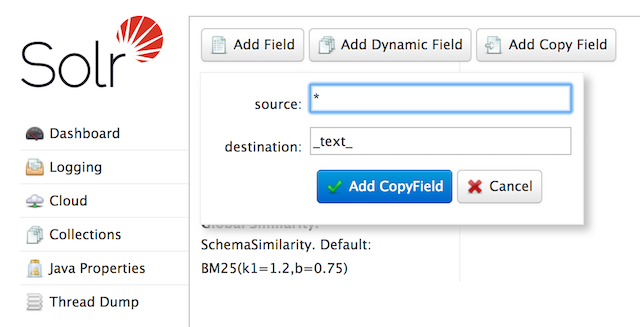
此操作會複製所有欄位,並將資料放入 "_text_" 欄位中。
| 在您的生產資料中執行此操作可能會非常耗費成本,因為它會指示 Solr 有效地將所有內容索引兩次。這會讓索引速度變慢,並使您的索引更大。在您的生產資料中,您會想要確定您只會複製那些真正值得您應用程式複製的欄位。 |
好的,現在我們可以索引資料並開始試用它了。
索引範例電影資料
我們要索引的電影資料位於您安裝的 example/films 目錄中。它有三種格式:JSON、XML 和 CSV。選擇其中一種格式並將其索引到「films」集合中 (在每個範例中,一個命令適用於 Unix/MacOS,另一個命令適用於 Windows)
$ bin/solr post -c films example/films/films.json
$ bin/solr post -c films example/films/films.xml$ bin/solr post -c films example/films/films.csv --params "f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=|"每個命令都包含以下主要參數:
-
-c films:這是要將資料索引至的 Solr 集合。 -
example/films/films.json(或films.xml或films.csv):這是要索引的資料檔案路徑。您可以簡單地提供此檔案所在的目錄,但是由於您知道要索引的格式,因此指定該格式的確切檔案會更有效率。
請注意,CSV 命令包含額外的參數。這是為了確保「genre」和「directed_by」欄中的多值條目會依據管道 (|) 字元分隔,該字元在此檔案中用作分隔符。告訴 Solr 以這種方式分割這些欄將確保資料正確索引。
每個命令都會產生類似於以下索引 JSON 時看到的輸出:
$ bin/solr post -c films example/films/films.json
Posting files to [base] url https://127.0.0.1:8983/solr/films/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file films.json (application/json) to [base]/json/docs
1 files indexed.
COMMITting Solr index changes to https://127.0.0.1:8983/solr/films/update...
Time spent: 0:00:00.878太棒了!
如果您前往電影的管理介面查詢畫面 (https://127.0.0.1:8983/solr/#/films/query) 並按下 執行查詢,您應該會看到 1100 個結果,並且前 10 個結果會顯示在螢幕上。
讓我們執行一個查詢,看看「catchall」欄位是否正常運作。在 q 方塊中輸入「comedy」,然後再次按下 執行查詢。您應該會看到 417 個結果。歡迎在我們繼續進行分面之前,試用其他搜尋。
分面
分面是 Solr 最受歡迎的功能之一。分面允許將搜尋結果排列成子集 (或儲存區或類別),並為每個子集提供計數。分面有幾種類型:欄位值、數值和日期範圍、樞紐 (決策樹) 以及任意查詢分面。
欄位分面
除了提供搜尋結果之外,Solr 查詢還可以傳回整個結果集中包含每個唯一值的文件的數量。
在管理介面查詢標籤上,如果您勾選 facet 核取方塊,您會看到出現一些與分面相關的選項:

若要查看所有文件的分面計數 (q=*:*):開啟分面 (facet=true),並透過 facet.field 參數指定要分面的欄位。如果您只需要分面,而不需要文件內容,請指定 rows=0。以下 curl 命令會傳回 genre_str 欄位的分面計數:
$ curl "https://127.0.0.1:8983/solr/films/select?q=\*:*&rows=0&facet=true&facet.field=genre_str"`在您的終端機中,您會看到類似以下的內容:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":11,
"params":{
"q":"*:*",
"facet.field":"genre_str",
"rows":"0",
"facet":"true"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"genre_str":[
"Drama",552,
"Comedy",389,
"Romance Film",270,
"Thriller",259,
"Action Film",196,
"Crime Fiction",170,
"World cinema",167]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}}我們在這裡稍微截斷了輸出,但是在 facet_counts 區段中,您會看到預設情況下,針對索引中的每個類型,您會取得使用每個類型的文件數的計數。Solr 有一個參數 facet.mincount,您可以使用它來限制僅包含一定數量文件的分面 (此參數未顯示在使用者介面中)。或者,您可能想要所有分面,並讓您應用程式的前端控制它向使用者顯示的方式。
如果您想要控制儲存區中的項目數,您可以執行類似以下的作業:
$ curl "https://127.0.0.1:8983/solr/films/select?=&q=\*:*&facet.field=genre_str&facet.mincount=200&facet=on&rows=0"您應該只會看到傳回 4 個分面。
還有許多其他參數可用來幫助您控制 Solr 如何建構分面和分面清單。我們將在本練習中介紹其中一些參數,您也可以參考分面章節以取得更多詳細資訊。
範圍分面
對於數值或日期,通常希望將分面計數劃分為範圍,而不是離散值。使用我們先前練習中的 techproducts 範例資料,數值範圍分面的主要範例是 price。電影資料包含電影的發行日期,我們可以利用它來建立日期範圍分面,這是範圍分面的另一個常見用途。
Solr Admin UI 尚不支援範圍分面選項,因此您需要使用 curl 或類似的命令列工具來進行以下範例。
如果我們建構一個看起來像這樣的查詢
$ curl "https://127.0.0.1:8983/solr/films/select?q=*:*&rows=0\
&facet=true\
&facet.range=initial_release_date\
&facet.range.start=NOW/YEAR-25YEAR\
&facet.range.end=NOW\
&facet.range.gap=%2B1YEAR"這會請求所有電影,並要求它們按年份分組,從 25 年前(我們最早的發行日期是 2000 年)開始到今天結束。請注意,此查詢 URL 將 + 編碼為 %2B。
在終端機中您會看到
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"facet.range":"initial_release_date",
"facet.limit":"300",
"q":"*:*",
"facet.range.gap":"+1YEAR",
"rows":"0",
"facet":"on",
"facet.range.start":"NOW-25YEAR",
"facet.range.end":"NOW"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"initial_release_date":{
"counts":[
"1997-01-01T00:00:00Z",0,
"1998-01-01T00:00:00Z",0,
"1999-01-01T00:00:00Z",0,
"2000-01-01T00:00:00Z",80,
"2001-01-01T00:00:00Z",94,
"2002-01-01T00:00:00Z",112,
"2003-01-01T00:00:00Z",125,
"2004-01-01T00:00:00Z",166,
"2005-01-01T00:00:00Z",167,
"2006-01-01T00:00:00Z",173,
"2007-01-01T00:00:00Z",45,
"2008-01-01T00:00:00Z",13,
"2009-01-01T00:00:00Z",5,
"2010-01-01T00:00:00Z",1,
"2011-01-01T00:00:00Z",0,
"2012-01-01T00:00:00Z",0,
"2013-01-01T00:00:00Z",2,
"2014-01-01T00:00:00Z",0,
"2015-01-01T00:00:00Z",1,
"2016-01-01T00:00:00Z",0],
"gap":"+1YEAR",
"start":"1997-01-01T00:00:00Z",
"end":"2017-01-01T00:00:00Z"}},
"facet_intervals":{},
"facet_heatmaps":{}}}樞紐分面
另一種分面類型是樞紐分面,也稱為「決策樹」,它允許為所有各種可能的組合巢狀排列兩個或多個欄位。使用電影資料,樞紐分面可用於查看「戲劇」類別(genre_str 欄位)中有多少電影是由某位導演執導的。以下是如何取得此情境的原始資料
$ curl "https://127.0.0.1:8983/solr/films/select?q=\*:*&rows=0&facet=on&facet.pivot=genre_str,directed_by_str"這會產生以下回應,其中顯示每個類別和導演組合的分面
{"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1147,
"params":{
"q":"*:*",
"facet.pivot":"genre_str,directed_by_str",
"rows":"0",
"facet":"on"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"genre_str,directed_by_str":[{
"field":"genre_str",
"value":"Drama",
"count":552,
"pivot":[{
"field":"directed_by_str",
"value":"Ridley Scott",
"count":5},
{
"field":"directed_by_str",
"value":"Steven Soderbergh",
"count":5},
{
"field":"directed_by_str",
"value":"Michael Winterbottom",
"count":4}}]}]}}}我們也截斷了此輸出 - 您會在畫面上看到許多類型和導演。