圖形
使用者指南的此章節涵蓋了圖形表達式背後的語法和理論。提供了兩個主要圖形使用案例的範例:二分圖推薦器和使用時間圖形查詢進行事件關聯。
圖形
Solr 中索引的日誌記錄和其他資料之間存在連接,可以將其視為分散式圖形。圖形表達式提供了一種機制來識別圖形中的根節點並遍歷它們的連接。圖形遍歷的總體目標是具體化特定的子圖並執行連結分析以了解節點之間的連接。
在下面的幾個章節中,我們將回顧 Solr 圖形表達式背後的圖形理論。
子圖
子圖是較大圖形的節點和連接的較小子集。圖形表達式可讓您彈性地定義和具體化儲存在分散式索引中的較大圖形的子圖。
子圖扮演兩個重要角色
-
它們為連結分析提供本機內容。子圖的設計定義了連結分析的含義。
-
它們提供了一個前景圖,可以與背景索引進行比較,以進行異常偵測。
二分圖子圖
圖形表達式可用於具體化二分圖子圖。二分圖是一個圖形,其中節點分為兩個不同的類別。然後可以分析這兩個類別之間的連結,以研究它們如何相關。二分圖經常在協同篩選推薦系統的背景下進行討論。
購物籃和產品之間的二分圖是一個有用的範例。透過購物籃和產品之間的連結分析,我們可以確定哪些產品最常在同一個購物籃中購買。
在下面的範例中,有一個名為 baskets 的 Solr 集合,其中包含三個欄位
id:唯一 ID
basket_s:購物籃 ID
product_s:產品
集合中的每個記錄代表購物籃中的產品。同一個購物籃中的所有產品都共用相同的購物籃 ID。
讓我們考慮一個簡單的範例,我們想要尋找經常與奶油一起銷售的產品。為此,我們可以建立一個包含奶油的購物籃的二分圖子圖。我們不會將奶油本身包含在圖形中,因為它對尋找奶油的互補產品沒有幫助。
以下是以矩陣表示的二分圖子圖範例
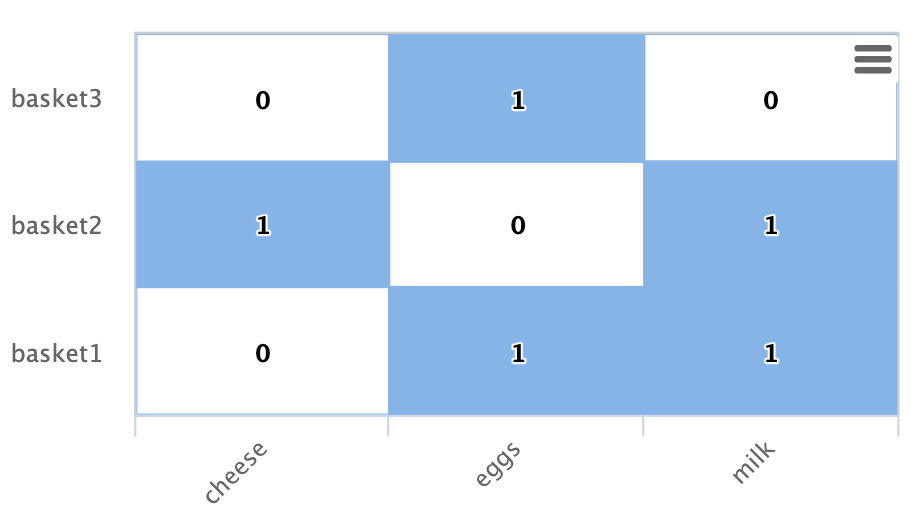
在此範例中,有三個購物籃由列表示:basket1、basket2、basket3。
也有三個產品由列表示:cheese、eggs、milk。
每個儲存格都有 1 或 0,表示產品是否在購物籃中。
讓我們看看 Solr 圖形表達式如何具體化這個二分圖子圖
nodes 函數用於從較大的圖形具體化子圖。以下是一個 nodes 函數的範例,它具體化了上面矩陣中顯示的二分圖。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true")讓我們從 random 函數開始分解這個範例
random(baskets, q="product_s:butter", fl="basket_s", rows="3")random 函數正在使用查詢 product_s:butter 搜尋 baskets 集合,並傳回 3 個隨機樣本。每個樣本都包含 basket_s 欄位,它是購物籃 ID。隨機樣本傳回的三個購物籃 ID 是圖形查詢的根節點。
nodes 函式是圖形查詢。nodes 函式操作的對象是由 random 函式回傳的三個根節點。它會透過比對根節點的 basket_s 欄位與索引中的 basket_s 欄位來「走訪」圖形。這會找出根購物籃的所有產品紀錄。然後,它會從走訪過程中找到的紀錄中「收集」product_s 欄位。會套用一個篩選器,讓 product_s 欄位中包含 butter 的紀錄不會被回傳。
trackTraversal 旗標會告知 nodes 表達式追蹤根購物籃與產品之間的連結。
節點集合
nodes 函式的輸出是一個節點集合,代表由 nodes 函式指定的子圖。節點集合包含圖形走訪期間收集的唯一節點集合。結果中的 node 屬性是收集節點的值。在購物籃範例中,node 屬性中包含 product_s 欄位,因為這是 nodes 表達式中指定要收集的內容。
購物籃圖形表達式的輸出如下
{
"result-set": {
"docs": [
{
"node": "eggs",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket3"
],
"level": 1
},
{
"node": "cheese",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket2"
],
"level": 1
},
{
"node": "milk",
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket2"
],
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 12
}
]
}
}結果中的 ancestors 屬性包含一個唯一的、依字母順序排序的集合,其中包含子圖中節點的所有入站連結。在此範例中,它會顯示連結到每個產品的購物籃。只有在 nodes 表達式中開啟 trackTraversal 旗標時,才會追蹤祖先連結。
連結分析與度中心性
通常會執行連結分析來判斷節點中心性。分析中心性時,目標是根據節點在子圖中的連結程度來為每個節點指定權重。節點中心性有不同的類型。圖形表達式可以非常有效率地計算入站度中心性(入度)。
入站度中心性的計算方式是計算每個節點的入站連結數量。為簡化起見,本文檔有時會將入站度簡稱為度。
回到購物籃範例
我們可以透過加總欄位來計算圖形中產品的度
cheese: 1
eggs: 2
milk: 2從度的計算中,我們知道eggs和milk在與 butter 一起購買的購物籃中出現的頻率比cheese高。
nodes 函式可以透過新增如下所示的 count(*) 聚合來計算度中心性
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*))此圖形表達式的輸出如下
{
"result-set": {
"docs": [
{
"node": "eggs",
"count(*)": 2,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket3"
],
"level": 1
},
{
"node": "cheese",
"count(*)": 1,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket2"
],
"level": 1
},
{
"node": "milk",
"count(*)": 2,
"collection": "baskets",
"field": "product_s",
"ancestors": [
"basket1",
"basket2"
],
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 17
}
]
}
}count(*) 聚合會計算「收集」的節點,在此範例中為 product_s 欄位中的值。請注意,count(*) 結果與祖先的數量相同。情況總是如此,因為 nodes 函式會先去除邊的重複資料,然後再計算收集的節點。因此,count(*) 聚合始終會計算收集節點的入站度中心性。
點積
入站度與二分圖推薦器之間存在直接關係,且與點積之間也存在直接關係。一旦我們包含 butter 的欄位,就可以在我們的範例中清楚地看到此關係
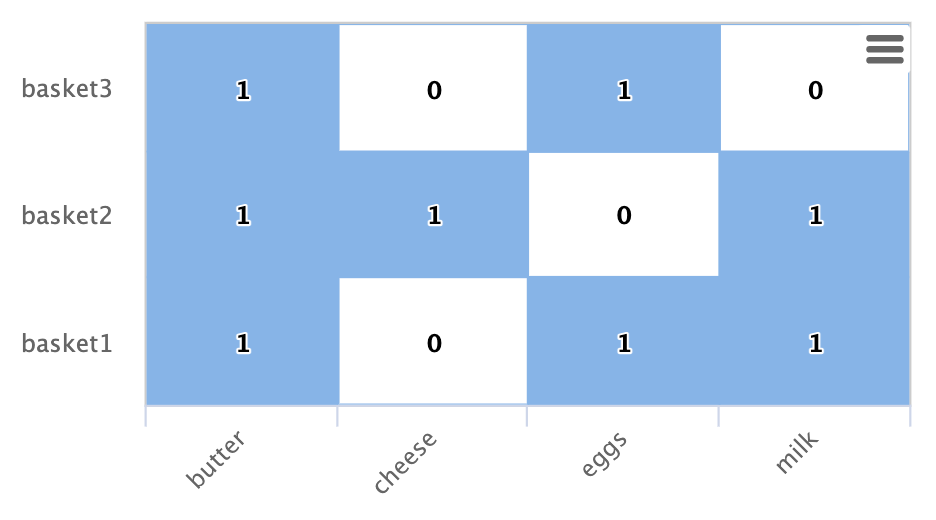
如果我們計算 butter 欄位與其他產品欄位之間的點積,您會發現點積等於每種情況下的入站度。這告訴我們,使用最大內積相似性的最近鄰居搜尋會選擇具有最高入站度的欄位。
限制購物籃出度
您可以透過限制購物籃的出度來增強推薦。出度是圖形中節點的出站連結數量。在購物籃範例中,購物籃的出站連結會連結到產品。因此,限制出度會限制購物籃的大小。
為什麼限制購物籃的大小會使推薦更強?為了回答這個問題,有助於將每個購物籃視為對與 butter 一起購買的產品進行投票。在有兩位候選人的選舉中,如果您同時投票給兩位候選人,這些選票會互相抵銷,且不會產生任何影響。但是,如果您只投票給一位候選人,您的選票會影響結果。相同的原則也適用於推薦。當一個購物籃投票給更多產品時,它會削弱其對任何一個產品的推薦強度。一個只包含 butter 和另一項商品的購物籃會更強烈地推薦該商品。
maxDocFreq 參數可用於限制圖形「走訪」,使其僅包含在索引中出現特定次數的購物籃。由於索引中每個購物籃 ID 的出現都是連到產品的連結,因此限制購物籃 ID 的文件頻率會限制購物籃的出度。maxDocFreq 參數是按分片套用的。如果只有單一分片或文件依購物籃 ID 共置,則 maxDocFreq 會是精確的計數。否則,它會回傳大小上限為 numShards * maxDocFreq 的購物籃。
以下範例顯示套用至 nodes 表達式的 maxDocFreq 參數。
nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
maxDocFreq="5",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*))節點評分
節點的度會描述子圖中有多少個節點連結到該節點。但是,這不會告訴我們節點是否對這個子圖特別重要,或者它是否只是整個圖形中非常頻繁的節點。在子圖中頻繁出現但在整個圖形中不頻繁出現的節點可以被視為與子圖更相關。
搜尋索引包含每個節點在整個索引中出現頻率的相關資訊。使用類似於 tf-idf 文件評分的技術,圖形表達式可以將節點的度與其在索引中的反向文件頻率結合,以判斷相關性分數。
scoreNodes 函式會對節點評分。以下是套用至購物籃節點集合的 scoreNodes 函式範例。
scoreNodes(nodes(baskets,
random(baskets, q="product_s:butter", fl="basket_s", rows="3"),
walk="basket_s->basket_s",
fq="-product_s:butter",
gather="product_s",
trackTraversal="true",
count(*)))現在輸出包含 nodeScore 屬性。在以下輸出中,請注意,即使 eggs 和 milk 具有相同的 count(*),eggs 的 nodeScore 也比 milk 高。這是因為 milk 在整個索引中出現的頻率比 eggs 高。nodeScore 函式新增的 docFreq 屬性會顯示索引中的文件頻率。由於 docFreq 較低,因此 eggs 會被認為與此子圖更相關,並且是與 butter 配對的更好推薦。
{
"result-set": {
"docs": [
{
"node": "eggs",
"nodeScore": 3.8930247,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 2,
"collection": "baskets",
"ancestors": [
"basket1",
"basket3"
],
"docFreq": 2
},
{
"node": "milk",
"nodeScore": 3.0281217,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 2,
"collection": "baskets",
"ancestors": [
"basket1",
"basket2"
],
"docFreq": 4
},
{
"node": "cheese",
"nodeScore": 2.7047482,
"field": "product_s",
"numDocs": 10,
"level": 1,
"count(*)": 1,
"collection": "baskets",
"ancestors": [
"basket2"
],
"docFreq": 1
},
{
"EOF": true,
"RESPONSE_TIME": 26
}
]
}
}時態圖形表達式
以上範例為時態圖形查詢奠定了基礎。時態圖形查詢允許 nodes 函式使用時間範圍來走訪圖形,以顯示時態圖形中的交互關聯。nodes 函式目前支援使用十秒視窗、每日視窗和工作日視窗的圖形走訪。
十秒視窗適用於記錄分析中的事件關聯和根本原因分析。每日和工作日視窗適用於關聯相隔數天發生的事件。
為了支援時態圖形查詢,必須在索引編制時將 ISO 8601 格式的截斷時間戳記作為字串欄位新增至記錄中。為了支援十秒時間視窗,應將十秒截斷時間戳記編製成字串欄位的索引,如下所示:2021-02-10T20:51:30Z。為了支援每日和每週時間視窗,應將每日截斷時間戳記編製成字串欄位的索引,如下所示:2021-02-10T00:00:00Z。
Solr 用於 Solr 記錄的索引工具(如此處所述)已經新增了十秒截斷時間戳記。因此,那些使用 Solr 來分析 Solr 記錄的人可以免費獲得時態圖形表達式。
根事件
一旦使用記錄對十秒視窗進行索引,我們就可以設計一個建立一組根事件的查詢。我們可以使用 Solr 記錄的範例來說明這一點。
在此範例中,我們將執行 Streaming Expression facet 聚合,以找出平均查詢時間最高的十個前十秒視窗。這些時間視窗可以用於表示時態圖形查詢中的慢速查詢事件。
以下是 facet 函式
facet(solr_logs, q="+type_s:query +distrib_s:false", buckets="time_ten_second_s", avg(qtime_i))以下是平均查詢時間最高的 25 個視窗的結果片段
{
"result-set": {
"docs": [
{
"avg(qtime_i)": 105961.38461538461,
"time_ten_second_s": "2020-08-25T21:05:00Z"
},
{
"avg(qtime_i)": 93150.16666666667,
"time_ten_second_s": "2020-08-25T21:04:50Z"
},
{
"avg(qtime_i)": 87742,
"time_ten_second_s": "2020-08-25T21:04:40Z"
},
{
"avg(qtime_i)": 72081.71929824562,
"time_ten_second_s": "2020-08-25T21:05:20Z"
},
{
"avg(qtime_i)": 62741.666666666664,
"time_ten_second_s": "2020-08-25T12:30:20Z"
},
{
"avg(qtime_i)": 56526,
"time_ten_second_s": "2020-08-25T12:41:20Z"
},
...
{
"avg(qtime_i)": 12893,
"time_ten_second_s": "2020-08-25T17:28:10Z"
},
{
"EOF": true,
"RESPONSE_TIME": 34
}
]
}
}時態二分圖
一旦我們識別出一組根事件,就可以輕鬆執行圖形查詢,以建立在同一十秒視窗內發生的記錄事件類型二分圖。使用 Solr 記錄時,有一個稱為 type_s 的欄位,它是記錄事件的類型。
為了查看在我們的根事件的同一個十秒視窗中發生了哪些記錄事件,我們可以「走訪」十秒視窗並收集 type_s 欄位。
nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
count(*))以下是產生的節點集合
{
"result-set": {
"docs": [
{
"node": "query",
"count(*)": 10,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "admin",
"count(*)": 2,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "other",
"count(*)": 3,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "update",
"count(*)": 2,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "error",
"count(*)": 1,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 50
}
]
}
}在此結果集中,node 欄位包含在與根事件相同的十秒視窗內發生的記錄事件類型。請注意,事件類型包括:查詢、管理、更新和錯誤。count(*) 顯示不同記錄事件類型的度中心性。
請注意,在慢速查詢事件的同一個十秒視窗內只有一個錯誤事件。
視窗參數
對於事件關聯和根本原因分析,僅找到相同十秒根事件視窗內發生的事件是不夠的。需要的是尋找在每個根事件之前的時間視窗內發生的事件。window 參數允許您將此先前的時間視窗指定為查詢的一部分。視窗參數是一個整數,用於指定圖形走訪中要包含的每個根事件視窗之前的十秒時間視窗數量。
nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
window="-3",
count(*))請注意,此範例中的視窗參數為負數 (-3)。這會從事件開始倒退時間。正數視窗會向前走訪時間。
以下是新增視窗參數時回傳的節點集合。請注意,在慢速查詢事件之前的 3 個十秒視窗內,現在有 29 個錯誤事件。
{
"result-set": {
"docs": [
{
"node": "query",
"count(*)": 62,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "admin",
"count(*)": 41,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "other",
"count(*)": 48,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "update",
"count(*)": 11,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"node": "error",
"count(*)": 29,
"collection": "solr_logs",
"field": "type_s",
"level": 1
},
{
"EOF": true,
"RESPONSE_TIME": 117
}
]
}
}度作為關聯的表示
透過對時態二分圖執行連結分析,我們可以計算指定時間視窗中發生的每個事件類型的度。我們在二分圖推薦器範例中確立了入站度與點積之間的直接關係。在數位訊號處理領域中,點積用於表示關聯。在我們的時態圖形查詢中,我們可以將入站度視為根事件與指定時間視窗內發生的事件之間關聯的表示。
延遲參數
了解關聯中的延遲對於某些使用案例非常重要。在延遲關聯中,一個事件發生,且在延遲後會發生另一個事件。視窗參數不會擷取延遲,因為我們只知道某個事件在先前視窗中的某處發生。
lag 參數可用於開始計算過去的若干個十秒視窗中的視窗參數。例如,我們可以從一組根事件之前的 30 秒開始,走訪 20 秒視窗中的圖形。透過調整延遲並重新執行查詢,我們可以判斷哪個延遲視窗具有最高的度。從這裡,我們可以判斷延遲。
節點評分與時態異常偵測
節點評分的概念可以應用於時間圖查詢,以找出與一組根事件 相關 且相對於這些根事件而言 異常 的事件。程度計算建立了事件之間的關聯性,但並未判斷該事件在整個圖中是否為非常常見的事件,或者是否特定於子圖。
可以應用 scoreNodes 函數來根據節點的程度以及節點詞彙在索引中的普遍性來評分節點。這將判斷事件對於根事件而言是否異常。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_ten_second_s",
avg(qtime_i)),
walk="time_ten_second_s->time_ten_second_s",
gather="type_s",
window="-3",
count(*)))以下是應用 scoreNodes 函數後的節點集合。現在我們看到 得分最高的節點 是 錯誤 事件。這個分數可以很好地指示我們從哪裡開始進行 根本原因分析。
{
"result-set": {
"docs": [
{
"node": "other",
"nodeScore": 23.441727,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 48,
"collection": "solr_logs",
"docFreq": 99737
},
{
"node": "query",
"nodeScore": 16.957537,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 62,
"collection": "solr_logs",
"docFreq": 449189
},
{
"node": "admin",
"nodeScore": 22.829023,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 41,
"collection": "solr_logs",
"docFreq": 96698
},
{
"node": "update",
"nodeScore": 3.9480786,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 11,
"collection": "solr_logs",
"docFreq": 3838884
},
{
"node": "error",
"nodeScore": 26.62394,
"field": "type_s",
"numDocs": 4513625,
"level": 1,
"count(*)": 29,
"collection": "solr_logs",
"docFreq": 27622
},
{
"EOF": true,
"RESPONSE_TIME": 124
}
]
}
}日期和工作日時間視窗
若要切換到 日期 或 工作日 時間視窗,我們必須首先在日誌記錄的字串欄位中索引截斷為日期的 ISO 8601 時間戳。在下面的範例中,欄位 time_day_s 包含截斷為日期的時間戳。
然後,只需在 window 參數中指定 -3DAYS 即可。這會從預設的十秒時間視窗切換到每日視窗。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_day_s",
avg(qtime_i)),
walk="time_day_s->time_day_s",
gather="type_s",
window="-3DAYS",
count(*)))有時您可能需要在時間中向前或向後移動時跳過週末。這對於關聯在工作日交易的金融工具非常有用。WEEKDAYS 時間視窗將向前或向後移動指定的工作日数。
scoreNodes(nodes(solr_logs,
facet(solr_logs,
q="+type_s:query +distrib_s:false",
buckets="time_day_s",
avg(qtime_i)),
walk="time_day_s->time_day_s",
gather="type_s",
window="-3WEEKDAYS",
count(*)))