在 GKE 上探索 Apache Solr Operator v0.3.0
作者:Tim Potter
今年稍早,彭博社慷慨地將 Solr Operator 捐贈給 Apache 軟體基金會。最新的 v0.3.0 版本是 Apache 旗下的第一個版本,對於整個 Apache Solr 社群而言,代表一個重要的里程碑。此 Operator 是 Solr 的第一個衛星專案,由 Solr PMC 管理,但獨立於 Apache Solr 發布。現在社群擁有一個強大的工具,可將在規模化運行 Solr 時獲得的寶貴經驗和最佳實踐,轉化為 Kubernetes 上的自動化解決方案。
簡介
在這篇文章中,我將從 DevOps 工程師的角度探索 v0.3.0 版本,該工程師需要在 Kubernetes 上部署配置完善的 Solr 叢集。
Solr Operator 使在 Kubernetes 上開始使用 Solr 變得非常容易。如果您按照本機教學進行操作,您可以在短時間內在本機上啟動並運行 Solr 叢集。但是,對於部署到生產環境,還有三個額外的考量點:安全性、高可用性和效能監控。本指南的目的是幫助您規劃和實施這些重要的生產考量。
在深入了解細節之前,請花點時間查看下面的圖表,該圖表描述了由 Operator 部署到 Kubernetes 的 Solr 叢集的主要組件、配置和互動。當然,還有許多其他的 Kubernetes 物件在運作(密碼、服務帳戶等等),但該圖表僅顯示主要物件。
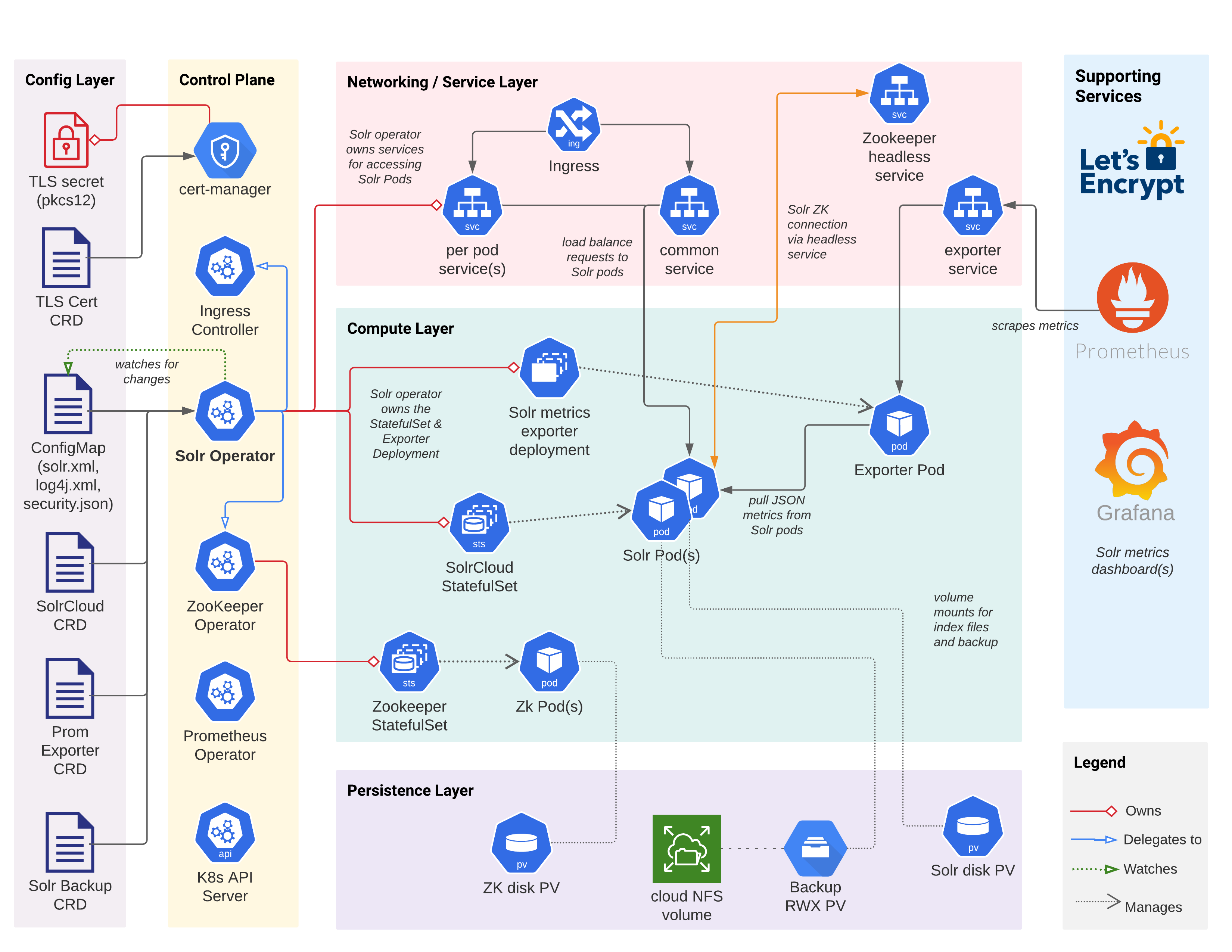
開始使用
讓我們在 GKE 上啟動並運行 Solr Operator、Solr 叢集和支援服務的基本部署。我與 Google 沒有正式的關係,並且在此文章中使用 GKE 是因為它易於使用,但相同的基本流程也適用於其他雲端託管的 Kubernetes,例如 Amazon 的 EKS 或 AKS。當我們完成本文檔的各個章節時,我們將改進此初始配置。最後,我們將擁有在雲端運行生產就緒的 Solr 叢集所需的 CRD 定義和支援腳本。
Kubernetes 設定
我鼓勵您在家中跟著操作,因此請啟動 GKE 叢集並打開您的終端機。如果您不熟悉 GKE,請在繼續閱讀本文檔之前,先完成GKE 快速入門。為了實現更好的 HA,您應該在三個區域中部署區域性 GKE 叢集(每個區域至少一個 Solr Pod)。當然,您可以將區域性叢集部署到一個區域以進行開發/測試,但我展示的範例基於在 us-central1 區域中運行的 3 節點 GKE 叢集,每個區域中都有一個節點。
首先,我們需要將 nginx ingress controller 安裝到 ingress-nginx 名稱空間中
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.45.0/deploy/static/provider/cloud/deploy.yaml
如需更多資訊,請參閱在 GKE 上部署 Nginx Ingress。
若要驗證 Ingress Controller 是否正常運作,請執行
kubectl get pods -l app.kubernetes.io/name=ingress-nginx -n ingress-nginx \
--field-selector status.phase=Running
應該會看到類似以下的預期輸出
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-6c94f69c74-fxzp7 1/1 Running 0 6m23s
在本文檔中,我們將把 Operator 和 Solr 部署到名為 sop030 的名稱空間中
kubectl create ns sop030
kubectl config set-context --current --namespace=sop030
Solr Operator 設定
如果您安裝了先前版本的 Solr Operator,請使用這些說明升級到 Apache Solr 版本:升級到 Apache。否則,請新增 Apache Solr Helm 儲存庫,安裝 Solr CRD 和 安裝 Solr Operator
helm repo add apache-solr https://solr.apache.org/charts
helm repo update
kubectl create -f https://solr.apache.org/operator/downloads/crds/v0.3.0/all-with-dependencies.yaml
helm upgrade --install solr-operator apache-solr/solr-operator \
--version 0.3.0
此時,請驗證您的名稱空間中是否有 Solr Operator Pod 正在執行
kubectl get pod -l control-plane=solr-operator
kubectl describe pod -l control-plane=solr-operator
請注意,我使用的是標籤選取器篩選器,而不是依 ID 尋址 Pod,這讓我不必尋找 ID 即可取得 Pod 詳細資訊。
您的名稱空間中也應該有一個 Zookeeper Operator Pod 正在執行,請使用以下命令驗證
kubectl get pod -l component=zookeeper-operator
Solr CRD
自訂資源定義 (CRD) 允許應用程式開發人員在 Kubernetes 中定義新型物件。這提供許多優勢
- 向人工操作員公開特定領域的配置設定
- 減少重複程式碼並隱藏實作細節
- 使用 kubectl 對 CRD 執行 CRUD 操作
- 如同任何其他 K8s 資源一樣,儲存在 etcd 中並進行管理
Solr Operator 定義代表 Solr 特定物件的 CRD,例如 SolrCloud 資源、指標匯出器資源以及備份/還原資源。SolrCloud CRD 定義在 Kubernetes 名稱空間中部署和管理 Solr 叢集所需的配置設定。首先,讓我們使用 kubectl 查看 SolrCloud CRD
# get a list of all CRDs in the cluster
kubectl get crds
# get details about the SolrCloud CRD Spec
kubectl explain solrclouds.spec
kubectl explain solrclouds.spec.solrImage
# get details about the SolrCloud CRD Status
kubectl explain solrclouds.status
請花點時間瀏覽以上 explain 命令的輸出;各種結構和欄位應該看起來很熟悉。隨時深入研究,探索 SolrCloud CRD Spec 和 Status 的不同部分。
建立 Solr Cloud
若要在 Kubernetes 名稱空間中部署 SolrCloud 物件的執行個體,我們需製作一些 YAML,如下列範例所示
apiVersion: solr.apache.org/v1beta1
kind: SolrCloud
metadata:
name: explore
spec:
customSolrKubeOptions:
podOptions:
resources:
limits:
memory: 3Gi
requests:
cpu: 700m
memory: 3Gi
dataStorage:
persistent:
pvcTemplate:
spec:
resources:
requests:
storage: 2Gi
reclaimPolicy: Delete
replicas: 3
solrImage:
repository: solr
tag: 8.8.2
solrJavaMem: -Xms500M -Xmx500M
updateStrategy:
method: StatefulSet
zookeeperRef:
provided:
chroot: /explore
image:
pullPolicy: IfNotPresent
repository: pravega/zookeeper
tag: 0.2.9
persistence:
reclaimPolicy: Delete
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
replicas: 3
zookeeperPodPolicy:
resources:
limits:
memory: 500Mi
requests:
cpu: 250m
memory: 500Mi
請密切注意 Solr 和 Zookeeper 的資源請求/限制和磁碟大小;為每個 Solr Pod 分配正確的記憶體、CPU 和磁碟空間是設計叢集時的基本任務。當然,使用 Kubernetes,您可以根據需要新增更多 Pod,但您仍然需要在部署 Pod 之前,根據您的使用案例估計正確的資源請求/限制和磁碟大小。生產環境的容量調整超出本文檔的範圍,而且非常依賴使用案例(通常需要運行一些實際的負載測試來試錯)。
您應該對 SolrCloud YAML 感到驚訝的是,大多數設定都非常特定於 Solr,如果您過去使用過 Solr,則不言自明。您的營運團隊會將此 YAML 保留在原始碼控制中,使他們能夠自動化在 Kubernetes 中建立 SolrCloud 叢集的流程。您甚至可以建立 Helm 圖表來管理您的 SolrCloud YAML 和相關物件,例如備份/還原和 Prometheus 匯出器 CRD 定義。
開啟 Shell 並執行以下命令以追蹤 Operator Pod 日誌
kubectl logs -l control-plane=solr-operator -f
請注意,我使用的是標籤選取器(-l ...)而不是依其 ID 尋址 Pod;這讓我每次想要檢視 Operator 日誌時,都不必尋找 Pod ID。
若要將 explore SolrCloud 部署到 K8s,請將上面顯示的 YAML 儲存到名為 explore-SolrCloud.yaml 的檔案中,然後在另一個 Shell 索引標籤中執行以下命令
kubectl apply -f explore-SolrCloud.yaml
我們將在本文檔的其餘部分中更新 explore-SolrCloud.yaml 檔案。
任何以「spec:」開頭的程式碼區段,都指的是此檔案。
當您將此 SolrCloud 定義提交到 Kubernetes API 伺服器時,它會使用類似觀察器機制通知 Solr Operator(作為 Pod 在您的名稱空間中執行)。這會在 Operator 中啟動協調流程,在該流程中,它會建立執行 explore SolrCloud 叢集所需的各種 K8s 物件(請參閱上圖)。在部署 SolrCloud 執行個體時,請簡要查看 Operator 的日誌。
CRD 的主要優點之一是您可以使用 kubectl 與它們互動,就像原生 K8s 物件一樣
$ kubectl get solrclouds
NAME VERSION TARGETVERSION DESIREDNODES NODES READYNODES AGE
explore 8.8.2 3 3 3 73s
$ kubectl get solrclouds explore -o yaml
在幕後,Operator 建立了一個 StatefulSet 來管理一組 Solr Pod。請使用以下命令查看 explore StatefulSet
kubectl get sts explore -o yaml
我正在依賴於此初始 SolrCloud 定義的一個細微設定
updateStrategy:
method: StatefulSet
我們需要從 StatefulSet 作為 updateStrategy 方法開始,以便我們可以在現有的 SolrCloud 上啟用 TLS。在啟用 TLS 後,我們會在 HA 章節中將其切換為 Managed。使用 Managed 需要 Operator 呼叫 collections API 來取得 CLUSTERSTATUS,這在叢集從 HTTP 轉換為 HTTPs 時無法運作。在實際部署中,您應該直接從一開始就啟用 TLS,而不是在現有叢集上升級到 TLS。
此外,我們暫時不要建立任何集合或載入資料,因為我們希望在繼續之前鎖定叢集。
Zookeeper 連線
Solr Cloud 依賴 Apache Zookeeper。在 explore SolrCloud 定義中,我使用的是提供的選項,這表示 Solr Operator 為 SolrCloud 執行個體提供一個 Zookeeper 集合。在幕後,Solr Operator 定義了一個 ZookeeperCluster CRD 執行個體,該執行個體由 Zookeeper Operator 管理。provided 選項對於入門和開發很有用,但不會公開 Zookeeper Operator 支援的所有配置選項。對於生產部署,請考慮在 SolrCloud CRD 定義之外定義您自己的 ZookeeperCluster,然後僅使用 spec.zookeeperRef 下的 connectionInfo 指向 Zookeeper 集合連線字串。這讓您可以完全控制 Zookeeper 叢集部署、允許多個 SolrCloud 執行個體(和其他應用程式)共用相同的 Zookeeper 服務(當然具有不同的 chroot),並提供良好的關注點分離。或者,Solr Operator 不需要使用 Zookeeper Operator,因此如果 Zookeeper Operator 無法滿足您的需求,您可以使用 Helm 圖表來部署您的 Zookeeper 叢集。
自訂 Log4J 設定
在繼續之前,我想指出 Operator 中的一個便捷功能,該功能允許您從使用者提供的 ConfigMap 載入自訂 Log4j 設定。我提到此功能是因為您可能面臨需要在生產環境中自訂 Solr 的 Log4j 設定,以協助解決問題的情況。我不會在此處深入探討詳細資訊,但請使用自訂記錄設定文件來設定您自己的自訂 Log4J 設定。
安全性
安全性應始終是您首要和主要的考量,尤其是在 GKE 等公有雲中執行時;您不會希望成為系統遭入侵的維運工程師。在本節中,我們將為 Solr 的 API 端點啟用 TLS、基本身份驗證和授權控制。如需所有配置選項的更詳細說明,請參閱 SolrCloud CRD 文件。
要為 Solr 啟用 TLS,您只需要一個包含公開 X.509 憑證和私鑰的 TLS 機密。Kubernetes 生態系統提供了一個用於頒發和管理憑證的強大工具:cert-manager。如果您的叢集中尚未安裝,請按照 Solr 運算符提供的基本說明安裝最新版本的 cert-manager:使用 cert-manager 頒發憑證。
Cert-manager 和 Let's Encrypt
首先,我們先從自簽憑證開始。您需要建立一個自簽發行者 (cert-manager CRD)、憑證 (cert-manager CRD) 和一個持有金鑰庫密碼的機密。將以下 YAML 儲存到檔案中,並透過 kubectl apply -f 應用它。
---
apiVersion: v1
kind: Secret
metadata:
name: pkcs12-keystore-password
stringData:
password-key: Test1234
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: selfsigned-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: explore-selfsigned-cert
spec:
subject:
organizations: ["self"]
dnsNames:
- localhost
secretName: explore-selfsigned-cert-tls
issuerRef:
name: selfsigned-issuer
keystores:
pkcs12:
create: true
passwordSecretRef:
key: password-key
name: pkcs12-keystore-password
請注意,我要求為我的憑證生成 PKCS12 金鑰庫,方法是使用
keystores:
pkcs12:
create: true
當使用基於 Java 的應用程式時,這是 cert-manager 的一個很棒的功能,因為 Java 原生支援讀取 PKCS12,而如果 cert-manager 沒有自動為您執行此操作,您將需要使用 keytool 轉換 tls.crt 和 tls.key 檔案。
Cert-manager 建立一個 Kubernetes 機密,其中包含 Solr 使用的 X.509 憑證、私鑰和符合 PKCS12 標準的金鑰庫。請花一點時間使用以下命令檢查機密的內容
kubectl get secret explore-selfsigned-cert-tls -o yaml
更新您的 explore-SolrCloud.yaml 中的 SolrCloud CRD 定義,以啟用 TLS 並指向持有金鑰庫的機密
spec:
...
solrAddressability:
commonServicePort: 443
external:
domainName: YOUR_DOMAIN_NAME_HERE
method: Ingress
nodePortOverride: 443
useExternalAddress: false
podPort: 8983
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
請注意,我也透過 Ingress 將 Solr 外部公開,並將通用服務埠切換為 443,這在使用啟用 TLS 的服務時更直觀。使用以下命令將您的變更應用到 SolrCloud CRD
kubectl apply -f explore-SolrCloud.yaml
這將觸發 Solr Pod 的滾動重新啟動,以使用您的自簽憑證啟用 TLS。透過開啟一個到其中一個 Solr Pod (埠 8983) 的埠轉發,然後執行以下操作,驗證 Solr 是否正在透過 HTTPS 提供流量
curl https://127.0.0.1:8983/solr/admin/info/system -k
Let's Encrypt 頒發的 TLS 憑證
自簽憑證非常適合用於本機測試,但為了在網路上公開服務,我們需要由受信任的 CA 頒發的憑證。我將使用 Let's Encrypt 為我擁有的網域的 Solr 叢集頒發憑證。如果您的 Solr 叢集沒有網域名稱,您可以跳過此部分,並在需要時再參考它。我在此使用的流程基於以下文件:Google 的 ACME DNS01 解析器。
以下是我為我的 GKE 環境建立的 Let's Encrypt 發行者
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: acme-letsencrypt-issuer
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email: *** REDACTED ***
privateKeySecretRef:
name: acme-letsencrypt-issuer-pk
solvers:
- dns01:
cloudDNS:
project: GCP_PROJECT
serviceAccountSecretRef:
name: clouddns-dns01-solver-svc-acct
key: key.json
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: explore-solr-tls-cert
spec:
dnsNames:
- YOUR_DOMAIN_NAME_HERE
issuerRef:
kind: Issuer
name: acme-letsencrypt-issuer
keystores:
pkcs12:
create: true
passwordSecretRef:
key: password-key
name: pkcs12-keystore-password
secretName: explore-solr-tls-letsencrypt
subject:
countries:
- USA
organizationalUnits:
- k8s
organizations:
- solr
建立憑證發行者通常涉及一些平台特定的配置。對於 GKE,請注意我正在使用 DNS01 解析器,這需要具有 DNS 管理權限的服務帳戶的憑證,您需要在您的 GCP 主控台中或使用 gcloud CLI 配置此憑證。在我的環境中,我將憑證儲存在一個名為:clouddns-dns01-solver-svc-acct 的機密中。
您可以追蹤 cert-manager Pod(在 cert-manager 命名空間中)的記錄,以追蹤發行過程的進度。
kubectl logs -l app.kubernetes.io/name=cert-manager -n cert-manager
一旦 Let's Encrypt 頒發了 TLS 憑證,請重新配置(假設您完成了上述自簽過程)您的 SolrCloud 執行個體,以透過 Ingress 公開 Solr,並使用 cert-manager 建立的 TLS 機密中儲存的憑證和私鑰的 PKCS12 金鑰庫
spec:
...
solrTLS:
pkcs12Secret:
name: explore-solr-tls-letsencrypt
key: keystore.p12
最後一步是建立 DNS A 記錄,以將 Ingress(由 Solr 運算符建立)的 IP 位址對應到您的 Ingress 的主機名稱。
mTLS
Solr 運算符支援啟用 mTLS 的 Solr 叢集,但這有點超出本文檔的範圍。如需配置 mTLS,請參閱 Solr 運算符文件。
身份驗證和授權
如果您遵循上一節中的流程,那麼 Solr Pod 之間的網路流量將被加密,但我們還需要確保傳入的請求具有使用者身份(身份驗證),並且請求的使用者被授權執行請求。從 v0.3.0 開始,Solr 運算符支援基本身份驗證和 Solr 的基於規則的授權控制。
最簡單的入門方法是讓運算符引導基本身份驗證和授權控制。如需詳細說明,請參閱:身份驗證和授權
spec:
...
solrSecurity:
authenticationType: Basic
運算符會為三個 Solr 使用者配置憑證:admin、k8s-oper 和 solr。
透過執行以下操作,以 admin 使用者身分登入 Solr 管理 Web UI
kubectl get secret explore-solrcloud-security-bootstrap \
-o jsonpath='{.data.admin}' | base64 --decode
此時,進出 Solr Pod 的所有流量都使用 TLS 加密,並且 API 端點透過 Solr 的基於規則的授權控制和基本身份驗證鎖定。現在 Solr 已正確鎖定,讓我們繼續配置我們的叢集以實現高可用性 (HA)。
高可用性
在本節中,我們將涵蓋在 Kubernetes 中實現 Solr Pod 高可用性的幾個關鍵主題。確保節點可用性只是等式的一部分。您還需要確保每個需要高可用性的集合的每個分片的副本都正確分佈在 Pod 中,以便在節點甚至整個 AZ 遺失時不會導致服務中斷。但是,確保在發生中斷時某些副本保持線上只能到此為止。在某些時候,健全的副本可能會因請求而超載,因此您制定的任何可用性策略也需要規劃健全副本負載突然增加的情況。
Pod 反親和性
為了開始我們對 Solr 運算符的高可用性的探索,讓我們確保使用 Pod 反親和性在叢集周圍均勻分佈 Solr Pod。
一旦您確定了所需的 Solr Pod 數量,您還需要使用Pod 反親和性規則,以平衡的方式將 Pod 分佈在 Kubernetes 叢集中,以便承受隨機節點故障以及區域級中斷(對於多區域叢集)。
若要查看叢集中每個節點的區域,請執行
kubectl get nodes -L topology.kubernetes.io/zone
在以下 podAntiAffinity 範例中,符合 solr-cloud=explore 標籤選擇器的 Pod 會分佈在叢集中不同的節點和區域中。
提示:Solr 運算符會將「solr-cloud」標籤設定為所有 Pod 上 SolrCloud 執行個體的名稱。
spec:
...
customSolrKubeOptions:
podOptions:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: topology.kubernetes.io/zone
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: kubernetes.io/hostname
顯然,當您在 3 個區域中有 3 個節點且有 3 個 Solr Pod 時,這並不重要,您只需使用主機名稱反親和性規則即可獲得均衡的分佈;對於大型叢集,同時具有主機名稱和區域的規則非常重要。
如果您沒有執行多區域叢集,則可以移除基於 topology.kubernetes.io/zone 的規則。此外,我認為此規則應該是一種偏好,而不是硬性要求,以便 Kubernetes 可以在一個區域關閉時在其他健全的區域中啟動替換節點和 Pod。
此外,當您為現有的 SolrCloud 應用這些反親和性規則時,您可能會遇到 Pod 排程問題,因為用於 Solr 磁碟的基礎持久性磁碟區聲明 (PVC) 會釘選到一個區域。根據新的反親和性規則移至另一個區域的任何 Solr Pod 都會使 Pod 處於 Pending 狀態,因為需要重新連接的 PVC 僅存在於原始區域中。因此,在推出 SolrCloud 叢集之前規劃您的 Pod 親和性規則是個好主意。
如果您需要的 Solr Pod 比叢集中可用的節點還多,那麼對於基於 kubernetes.io/hostname 的規則,您應該使用 preferredDuringSchedulingIgnoredDuringExecution 而不是 requiredDuringSchedulingIgnoredDuringExecution。Kubernetes 會盡力將 Pod 均勻分佈在節點上,但多個 Pod 會在某些時候排程在同一個節點上(顯然)。
假設您要求「explore」SolrCloud 有 3 個副本,則您應該在三個區域中均勻分佈 Pod。執行以下命令以取得您的 Solr Pod 正在執行所在的唯一節點數,並計算它們有多少個。
kubectl get po -l solr-cloud=explore,technology=solr-cloud \
-o json | jq -r '.items | sort_by(.spec.nodeName)[] | [.spec.nodeName] | @tsv' | uniq | wc -l
輸出應為:3
您應該對 Zookeeper Pod 採用類似的反親和性配置,以便將它們也分佈在各個區域中。
區域感知副本放置
一旦您的叢集 Pod 經過適當調整大小並分佈在叢集周圍以促進 HA,您仍然需要確保需要 HA 的集合的所有副本都放置到位,以便利用叢集佈局。換句話說,如果同一個分片的所有副本最終都位於同一個節點或區域中,則將 Pod 分佈在叢集周圍以支援 HA 沒有任何好處。在 Solr 方面,一個好的起始規則是讓同一個分片的副本偏好使用以下命令的其他主機
{"node": "#ANY", "shard": "#EACH", "replica":"<2"},
有關此和其他類型的規則的詳細資訊,請參閱 Solr 自動調整。
如果您過度分片您的集合,即總副本數 > Pod 數,則您可能需要放寬節點級別自動調整規則中的計數閾值。
注意:Solr 自動調整框架已在 8.x 中棄用,並在 9.x 中移除。但是,我們將在本文檔中用於副本放置的規則已由 9.x 中提供的 AffinityPlacementPlugin 取代,請參閱:solr/core/src/java/org/apache/solr/cluster/placement/plugins/AffinityPlacementFactory.java 以了解詳細資訊。
對於多 AZ 叢集,StatefulSet 中的每個 Solr Pod 都需要設定 availability_zone Java 系統屬性,這是一個唯一標籤,用於識別該 Pod 的區域。 availability_zone 屬性可以用於自動調整規則,以將副本分佈在 SolrCloud 叢集中所有可用的區域中。
{"replica":"#EQUAL", "shard":"#EACH", "sysprop.availability_zone":"#EACH"},
如果您的 Solr Pod 的服務帳戶具有取得節點的權限,您可以使用向下 API從節點中繼資料取得區域。但是,許多管理員不願意給予此權限。以下顯示了一個 GCP 特定解決方案,我們在此解決方案中 curl http://metadata.google.internal/computeMetadata/v1/instance/zone API
spec:
...
customSolrKubeOptions:
podOptions:
initContainers: # additional init containers for the Solr pods
- name: set-zone # GKE specific, avoids giving get nodes permission to the service account
image: curlimages/curl:latest
command:
- '/bin/sh'
- '-c'
- |
zone=$(curl -sS http://metadata.google.internal/computeMetadata/v1/instance/zone -H 'Metadata-Flavor: Google')
zone=${zone##*/}
if [ "${zone}" != "" ]; then
echo "export SOLR_OPTS=\"\${SOLR_OPTS} -Davailability_zone=${zone}\"" > /docker-entrypoint-initdb.d/set-zone.sh
fi
volumeMounts:
- name: initdb
mountPath: /docker-entrypoint-initdb.d
volumes:
- defaultContainerMount:
mountPath: /docker-entrypoint-initdb.d
name: initdb
name: initdb
source:
emptyDir: {}
請注意,initContainer 會將 set-zone.sh 腳本新增至 /docker-entrypoint-initdb.d。Docker Solr 框架會在啟動 Solr 之前,先執行此目錄中的任何腳本。類似的方法也可以應用於 EKS (請參閱 http://169.254.169.254/latest/dynamic/instance-identity/document 的輸出)。當然,使用特定平台的方法並非理想,但也不需要授與取得節點的權限。關鍵是使用任何適用於您系統的方法來設定 availability_zone 系統屬性。
您還需要確保分散式查詢偏好同區域的其他副本,方法是使用 Solr 8.2 中新增的 node.sysprop shardPreference。當兩個區域都健康時,此查詢路由偏好也有助於減少跨區域的查詢。如需更多詳細資訊,請查閱 Solr 參考指南 - Shard Preferences
我將把使用 availability_zone 系統屬性來影響副本放置的自動調整政策,留給讀者自行練習。
副本類型
如果您使用運算子部署多個 SolrCloud 實例,但它們都使用相同的 Zookeeper 連接字串 (和 chroot),那麼從 Solr 的角度來看,其行為就像單個 Solr Cloud 叢集。您可以使用此方法將 Solr Pod 指派給 Kubernetes 叢集中的不同節點。例如,您可能希望在一組節點上執行 TLOG 副本,而在另一組節點上執行 PULL 副本,以隔離寫入和讀取流量 (請參閱:副本類型)。依副本類型隔離流量超出本文檔的範圍,但您可以使用運算子部署多個 SolrCloud 實例來實現隔離。每個實例都需要設定一個 Java 系統屬性,例如 solr_node_type,以區分彼此的 Solr Pod;Solr 的自動調整政策引擎支援使用系統屬性來指派副本類型。
滾動重新啟動
運算子的主要優點之一是我們可以擴展 Kubernetes 的預設行為,以考量應用程式特定的狀態。例如,在執行 StatefulSet 的滾動重新啟動時,K8s 會從具有最高序數值的 Pod 開始,並依序向下到零,然後在重新啟動的 Pod 達到 Running 狀態之間等待。雖然此方法有效,但對於大型叢集來說,通常太慢,而且如果不知道該節點上的副本是否正在復原,則可能會造成危害。
相反地,運算子增強了 StatefulSet 的滾動重新啟動操作,以考量哪個 Solr Pod 主機 Overseer (最後重新啟動)、Pod 上的領導者數量等等。結果是為 SolrCloud 最佳化的滾動重新啟動程序,其中可以同時重新啟動多個 Pod。運算子使用 Solr 的叢集狀態 API 來確保在決定要同時重新啟動哪些 Pod 時,每個分片的至少一個副本*在線上。更重要的是,這些自訂的協調程序會遵守 Kubernetes 中非常重要的冪等性概念。給定相同的起始狀態,呼叫協調程序 100 次,其結果應該與第 1 次和第 100 次相同。
回想一下,我最初使用 StatefulSet 方法是為了讓我們能夠將現有叢集遷移以使用 TLS。讓我們切換為使用以下組態的 Managed 方法
spec:
...
updateStrategy:
managed:
maxPodsUnavailable: 2
maxShardReplicasUnavailable: 2
method: Managed
將此新增至您的 explore-SolrCloud.yaml 並套用變更。
* 如您在上方所見,Managed 更新策略是可自訂的,並且可以設定為您所需的安全或快速程度。請參閱更新文件以取得更多資訊。
效能監控
現在我們有一個安全、具備高可用性的 Solr 叢集,由 Solr 運算子部署和管理。我要介紹的最後一部分是使用 Prometheus stack 進行效能監控。
Prometheus Stack
您可能已經在使用 Prometheus 進行監控,但如果您的叢集中尚未安裝,請使用安裝說明來安裝包含 Grafana 的 Prometheus stack。
Prometheus Exporter
運算子文件涵蓋如何為您的 SolrCloud 實例部署 Prometheus exporter。由於我們啟用了基本驗證和 TLS,您需要確保 exporter 可以使用以下組態設定與受保護的 Solr Pod 通訊
solrReference:
cloud:
name: "explore"
basicAuthSecret: explore-solrcloud-basic-auth
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
請確認 pkcs12Secret.name 是否正確,取決於您使用的是自我簽署的憑證還是由其他 CA (例如 Let's Encrypt) 簽發的憑證。
確保 Prometheus 運算子從中抓取指標的服務是正確的
kubectl get svc -l solr-prometheus-exporter=explore-prom-exporter
如果這顯示服務健康,則建立一個服務監控器,以觸發 Prometheus 從 exporter Pod 透過 explore-prom-exporter-solr-metrics 服務開始抓取指標。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: solr-metrics
labels:
release: prometheus-stack
spec:
selector:
matchLabels:
solr-prometheus-exporter: explore-prom-exporter
namespaceSelector:
matchNames:
- sop030
endpoints:
- port: solr-metrics
interval: 15s
您需要先在叢集中建立至少一個集合,然後 exporter 才會開始產生有用的指標。
Grafana 儀表板
使用 kubectl expose 為 Grafana 建立 LoadBalancer (外部 IP)
kubectl expose deployment prometheus-stack-grafana --type=LoadBalancer \
--name=grafana -n monitoring
等待片刻後,透過執行以下操作取得 Grafana 服務的外部 IP 位址
kubectl -n monitoring get service grafana \
-o jsonpath='{.status.loadBalancer.ingress[0].ip}'
或者,您可以直接開啟一個連接埠轉發至 Grafana Pod,並在連接埠 3000 上接聽。
使用 admin 和 prom-operator 登入 Grafana
從來源發行下載預設的 Solr 儀表板
wget -q -O grafana-solr-dashboard.json \
"https://raw.githubusercontent.com/apache/lucene-solr/branch_8x/solr/contrib/prometheus-exporter/conf/grafana-solr-dashboard.json"
將 grafana-solr-dashboard.json 檔案手動匯入 Grafana。
此時,您應該載入一些資料並執行查詢效能測試。如果您正在執行多區域叢集,請務必將下列查詢參數新增至您的查詢請求,以偏好同區域的副本 (這有助於在所有區域都有健康副本時,減少每個請求的跨區域流量)。如果您沒有查詢負載測試工具,那麼我建議您查看 Gatling (gatling.io)。
shards.preference=node.sysprop:sysprop.availability_zone,replica.location:local
總結
此時,您現在有了一個藍圖,用於建立透過 Prometheus 和 Grafana 進行效能監控的安全、具備高可用性且平衡的 Solr 叢集。在推出到生產環境之前,您還需要考慮備份/還原、自動調整和針對關鍵健康指標的警示。希望我能在未來的文章中介紹其中一些額外方面。
還有其他您想了解更多資訊的疑慮嗎?請告訴我們,我們在 Slack 上 #solr-operator 或透過 GitHub Issues。
這是我在這篇文章中使用的 SolrCloud、Prometheus Exporter 和支援物件 YAML 的最終清單。請享用!
---
apiVersion: v1
kind: Secret
metadata:
name: pkcs12-keystore-password
stringData:
password-key: Test1234
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: selfsigned-issuer
spec:
selfSigned: {}
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: explore-selfsigned-cert
spec:
subject:
organizations: ["self"]
dnsNames:
- localhost
secretName: explore-selfsigned-cert-tls
issuerRef:
name: selfsigned-issuer
keystores:
pkcs12:
create: true
passwordSecretRef:
key: password-key
name: pkcs12-keystore-password
---
apiVersion: solr.apache.org/v1beta1
kind: SolrCloud
metadata:
name: explore
spec:
customSolrKubeOptions:
podOptions:
resources:
limits:
memory: 3Gi
requests:
cpu: 700m
memory: 3Gi
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: topology.kubernetes.io/zone
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "technology"
operator: In
values:
- solr-cloud
- key: "solr-cloud"
operator: In
values:
- explore
topologyKey: kubernetes.io/hostname
initContainers: # additional init containers for the Solr pods
- name: set-zone # GKE specific, avoids giving get nodes permission to the service account
image: curlimages/curl:latest
command:
- '/bin/sh'
- '-c'
- |
zone=$(curl -sS http://metadata.google.internal/computeMetadata/v1/instance/zone -H 'Metadata-Flavor: Google')
zone=${zone##*/}
if [ "${zone}" != "" ]; then
echo "export SOLR_OPTS=\"\${SOLR_OPTS} -Davailability_zone=${zone}\"" > /docker-entrypoint-initdb.d/set-zone.sh
fi
volumeMounts:
- name: initdb
mountPath: /docker-entrypoint-initdb.d
volumes:
- defaultContainerMount:
mountPath: /docker-entrypoint-initdb.d
name: initdb
name: initdb
source:
emptyDir: {}
dataStorage:
persistent:
pvcTemplate:
spec:
resources:
requests:
storage: 2Gi
reclaimPolicy: Delete
replicas: 3
solrImage:
repository: solr
tag: 8.8.2
solrJavaMem: -Xms500M -Xmx510M
updateStrategy:
managed:
maxPodsUnavailable: 2
maxShardReplicasUnavailable: 2
method: Managed
solrAddressability:
commonServicePort: 443
external:
domainName: YOUR_DOMAIN_NAME_HERE
method: Ingress
nodePortOverride: 443
useExternalAddress: false
podPort: 8983
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
solrSecurity:
authenticationType: Basic
zookeeperRef:
provided:
chroot: /explore
image:
pullPolicy: IfNotPresent
repository: pravega/zookeeper
tag: 0.2.9
persistence:
reclaimPolicy: Delete
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
replicas: 3
zookeeperPodPolicy:
resources:
limits:
memory: 500Mi
requests:
cpu: 250m
memory: 500Mi
---
apiVersion: solr.apache.org/v1beta1
kind: SolrPrometheusExporter
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: explore-prom-exporter
spec:
customKubeOptions:
podOptions:
resources:
requests:
cpu: 300m
memory: 800Mi
solrReference:
cloud:
name: "explore"
basicAuthSecret: explore-solrcloud-basic-auth
solrTLS:
restartOnTLSSecretUpdate: true
pkcs12Secret:
name: explore-selfsigned-cert-tls
key: keystore.p12
keyStorePasswordSecret:
name: pkcs12-keystore-password
key: password-key
numThreads: 6
image:
repository: solr
tag: 8.8.2
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: solr-metrics
labels:
release: prometheus-stack
spec:
selector:
matchLabels:
solr-prometheus-exporter: explore-prom-exporter
namespaceSelector:
matchNames:
- sop030
endpoints:
- port: solr-metrics
interval: 15s